

























Fabrice AI: Triển khai kỹ thuật hiện tại
Trong bài đăng trước, Fabrice AI: Hành trình kỹ thuật , tôi đã giải thích hành trình chúng tôi đã trải qua để xây dựng Fabrice AI theo một vòng tròn hoàn chỉnh. Tôi bắt đầu bằng cách sử dụng Chat GPT 3 và 3.5. Thất vọng với kết quả, tôi đã thử sử dụng Langchain Framework để xây dựng mô hình AI của riêng mình trên đó, trước khi quay lại Chat GPT khi họ bắt đầu sử dụng cơ sở dữ liệu vector và cải thiện đáng kể kết quả với 4o.
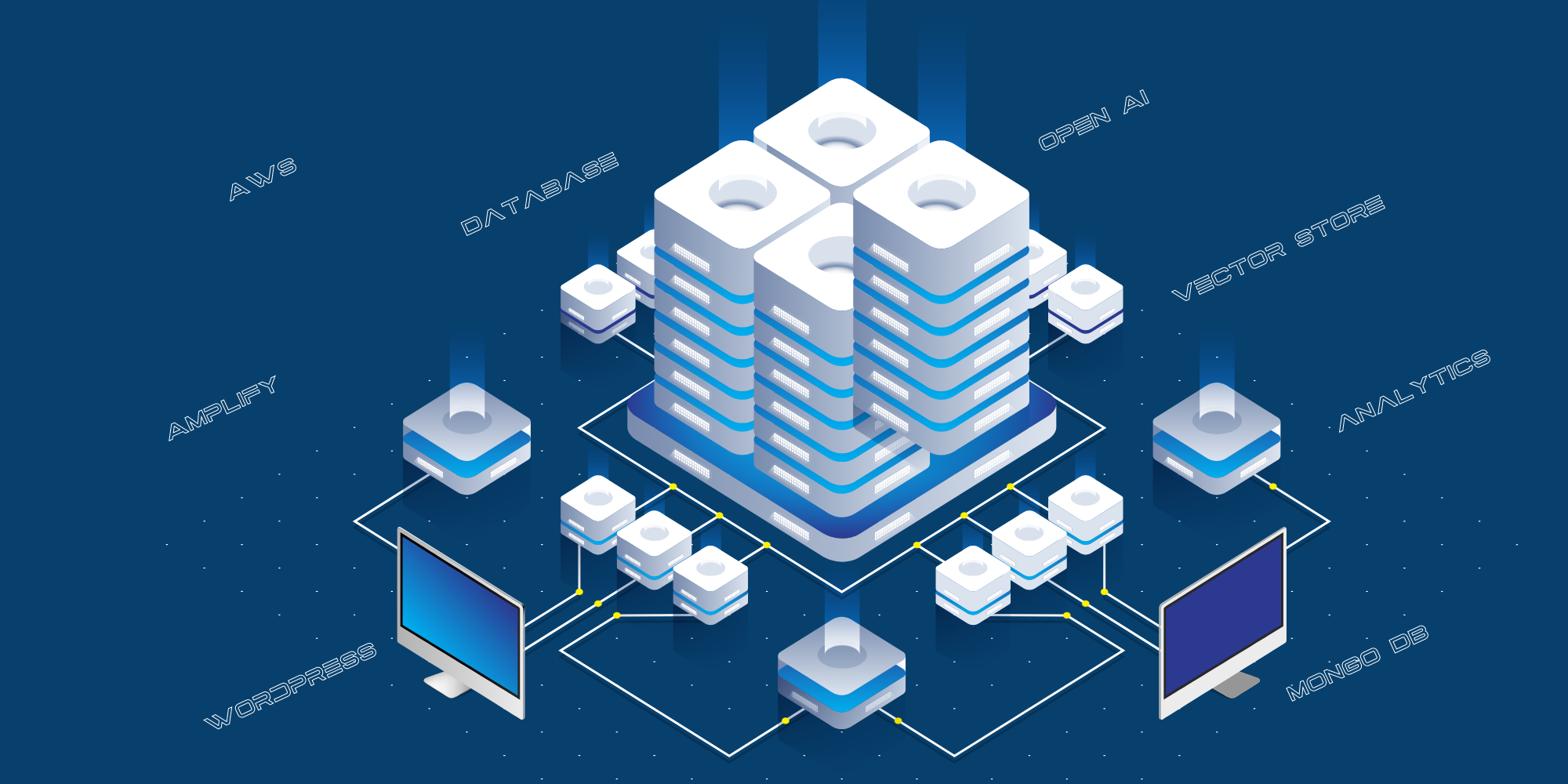
Sau đây là quy trình hiện tại để đào tạo Fabrice AI:
- Dữ liệu đào tạo (bài đăng trên blog, URL Youtube, URL podcast, URL PDF và URL hình ảnh) được lưu trữ trong cơ sở dữ liệu WordPress của chúng tôi.
- Chúng tôi trích xuất dữ liệu và cấu trúc nó.
- Chúng tôi cung cấp dữ liệu có cấu trúc cho Open AI để đào tạo bằng cách sử dụng API Trợ lý .
- Sau đó, Open AI sẽ tạo cơ sở dữ liệu lưu trữ vector và lưu trữ nó.
Đây là ví dụ về một phần dữ liệu có cấu trúc. Mỗi phần nội dung có tệp JSON riêng. Chúng tôi đảm bảo không vượt quá giới hạn 32.000 mã thông báo.
{
“mã số”: “1”,
“ngày”: ” “,
“liên kết”:”https://fabricegrinda.com/”,
“tiêu đề”: {
“rendered”: “Fabrice AI là gì?”
},
“Thể loại”: “Về Fabrice”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“other_media”: “”,
“knowledge_type”: “blog”,
“contentUpdated”: “Fabrice AI là bản trình bày kỹ thuật số về suy nghĩ của Fabrice dựa trên các bài đăng trên blog của ông và các podcast và cuộc phỏng vấn được chọn lọc bằng ChatGPT. Vì nhiều bản ghi chép không được ghi chép đầy đủ và blog chỉ là bản trình bày hạn chế về Fabrice, chúng tôi xin lỗi vì những thông tin không chính xác và thiếu sót. Tuy nhiên, đây là điểm khởi đầu tốt để biết được suy nghĩ của Fabrice về nhiều chủ đề.”
}
Đây là triển khai kỹ thuật hiện tại:
- Trang web dành cho người tiêu dùng được lưu trữ trên AWS Amplify .
- Việc tích hợp giữa trang web công cộng và Open AI được thực hiện thông qua lớp API, được lưu trữ trên AWS dưới dạng máy chủ API Python.
- Chúng tôi sử dụng MongoDB như một nhật ký để lưu trữ tất cả các câu hỏi của công chúng, các câu trả lời do Chat GPT đưa ra và URL của các nguồn.
- Chúng tôi sử dụng nhiều tập lệnh khác nhau để cấu trúc dữ liệu từ blog, YouTube, v.v. để chuyển sang Open AI để đào tạo.
- Chúng tôi sử dụng React-Speech Recognition để chuyển đổi câu hỏi bằng giọng nói thành văn bản.
- Chúng tôi cũng sử dụng Google Analytics để theo dõi lưu lượng truy cập trang web.
Điều quan trọng cần lưu ý là chúng tôi sử dụng hai trợ lý:
- Một cái để trả lời câu hỏi.
- Một là để lấy URL siêu dữ liệu, URL blog có nội dung gốc để hiển thị nguồn ở cuối câu trả lời.
Tiếp theo là gì?
- Cải tiến chuyển giọng nói thành văn bản
Mô hình Whisper của Open AI cho giọng nói thành văn bản chính xác hơn React. Nó cũng hỗ trợ nhiều ngôn ngữ ngay khi cài đặt và xử lý tốt giọng nói, giọng địa phương và giọng nói hỗn hợp. Do đó, tôi rất có thể sẽ chuyển sang nó trong những tháng tới. Điều đó có nghĩa là nó phức tạp hơn để thiết lập nên có thể mất một thời gian. Bạn cần xử lý mô hình, quản lý các phụ thuộc (ví dụ: Python, thư viện) và đảm bảo bạn có đủ phần cứng để có hiệu suất hiệu quả. Ngoài ra, Whisper không được thiết kế để sử dụng trực tiếp trong trình duyệt. Khi xây dựng ứng dụng web, bạn cần tạo một dịch vụ phụ trợ để xử lý bản ghi, điều này làm tăng thêm tính phức tạp.
- Avatar AI của Fabrice
Tôi muốn tạo một Avatar Fabrice AI trông và nghe giống tôi để bạn có thể trò chuyện. Tôi đã đánh giá D-iD nhưng thấy nó quá đắt so với mục đích của tôi. Eleven Labs chỉ có giọng nói. Synthesia rất tuyệt nhưng hiện tại không tạo video theo thời gian thực. Cuối cùng, tôi quyết định sử dụng HeyGen vì giá cả và chức năng phù hợp hơn.
Tôi ngờ rằng tại một thời điểm nào đó Open AI sẽ phát hành giải pháp riêng của mình nên công sức này sẽ trở nên vô ích. Tôi thấy thoải mái với điều đó và sẽ chuyển sang giải pháp Open AI khi và nếu có. Ở giai đoạn này, mục đích của toàn bộ bài tập này là tìm hiểu những gì có thể với AI và lượng công việc cần thiết để giúp tôi hiểu rõ hơn về không gian này.
- Bảng điều khiển tùy chỉnh
Hiện tại, tôi cần chạy truy vấn MongoDB để trích xuất các câu hỏi và câu trả lời trong ngày. Tôi đang xây dựng một bảng điều khiển đơn giản, nơi tôi có thể trích xuất và thống kê đơn giản về số lượng truy vấn theo ngôn ngữ, số lượng yêu cầu chuyển giọng nói thành văn bản, v.v.
- Nguồn dữ liệu bổ sung
Chúng tôi vừa tải FJ Labs Portfolio lên Fabrice AI. Bây giờ bạn có thể hỏi liệu một công ty có nằm trong danh mục đầu tư hay không. Fabrice AI trả lời bằng mô tả ngắn gọn về công ty và liên kết đến trang web của công ty.

Vì Fabrice AI nhận được rất nhiều câu hỏi cá nhân mà không có câu trả lời, nên tôi đã dành thời gian gắn thẻ thủ công từng diễn giả trong Video mừng sinh nhật lần thứ 50 của mình để cung cấp nội dung cần thiết.

Phần kết luận
Với tất cả công việc tôi đã làm trong mười hai tháng qua về mọi thứ liên quan đến AI, có vẻ như có một kết luận chung rõ ràng: bạn càng đợi lâu, thì càng rẻ, càng dễ và càng tốt, và khả năng Open AI sẽ cung cấp nó càng cao! Trong thời gian chờ đợi, hãy cho tôi biết nếu bạn có bất kỳ câu hỏi nào.