

























Fabrice AI: موجودہ تکنیکی عمل درآمد
پچھلی پوسٹ میں، Fabrice AI: The Technical Journey میں نے اس سفر کی وضاحت کی جس سے ہم Fabrice AI بنانے کے لیے ایک مکمل دائرہ بنا رہے تھے۔ میں نے چیٹ GPT 3 اور 3.5 استعمال کرکے شروع کیا۔ نتائج سے مایوس ہو کر، میں نے Langchain Framework کو استعمال کرنے کی کوشش کی تاکہ اس کے اوپر اپنا AI ماڈل بنایا جا سکے، Chat GPT پر واپس آنے سے پہلے جب انہوں نے ویکٹر ڈیٹا بیس کا استعمال شروع کر دیا اور 4o کے ساتھ بڑے پیمانے پر نتائج کو بہتر بنایا۔
Fabrice AI کی تربیت کا موجودہ عمل یہ ہے:
- تربیتی ڈیٹا (بلاگ پوسٹس، یوٹیوب یو آر ایل، پوڈ کاسٹ یو آر ایل، پی ڈی ایف یو آر ایل اور امیج یو آر ایل) ہمارے ورڈپریس ڈیٹا بیس میں محفوظ ہے۔
- ہم ڈیٹا نکالتے ہیں اور اس کی ساخت بناتے ہیں۔
- ہم اسسٹنٹ API کا استعمال کرتے ہوئے تربیت کے لیے اوپن AI کو منظم ڈیٹا فراہم کرتے ہیں۔
- اوپن اے آئی پھر ویکٹر اسٹور ڈیٹا بیس بناتا ہے اور اسے اسٹور کرتا ہے۔
یہاں سٹرکچرڈ ڈیٹا کے ایک ٹکڑے کی ایک مثال ہے۔ مواد کے ہر ٹکڑے کی اپنی JSON فائل ہوتی ہے۔ ہم یقینی بناتے ہیں کہ 32,000 ٹوکن کی حد سے تجاوز نہ کریں۔
{
"id”: "1”,
"تاریخ”: "”،
"link”:”https://fabricegrinda.com/”,
"عنوان”: {
"rendered”: "Fabrice AI کیا ہے؟”
},
"زمرہ”: "فیبریس کے بارے میں”
"featured_media”: "https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
"other_media”: "”,
"knowledge_type”: "بلاگ”،
"contentUpdated”: "Fabrice AI Fabrice کے خیالات کی ڈیجیٹل نمائندگی ہے جو اس کی بلاگ پوسٹس اور ChatGPT کا استعمال کرتے ہوئے نقل شدہ پوڈکاسٹ اور انٹرویوز پر مبنی ہے۔ ہم غلطیوں اور گمشدہ معلومات کے لیے معذرت خواہ ہیں۔ بہت سے موضوعات پر فیبریس کے خیالات حاصل کرنے کے لیے ایک اچھا نقطہ آغاز۔”
}
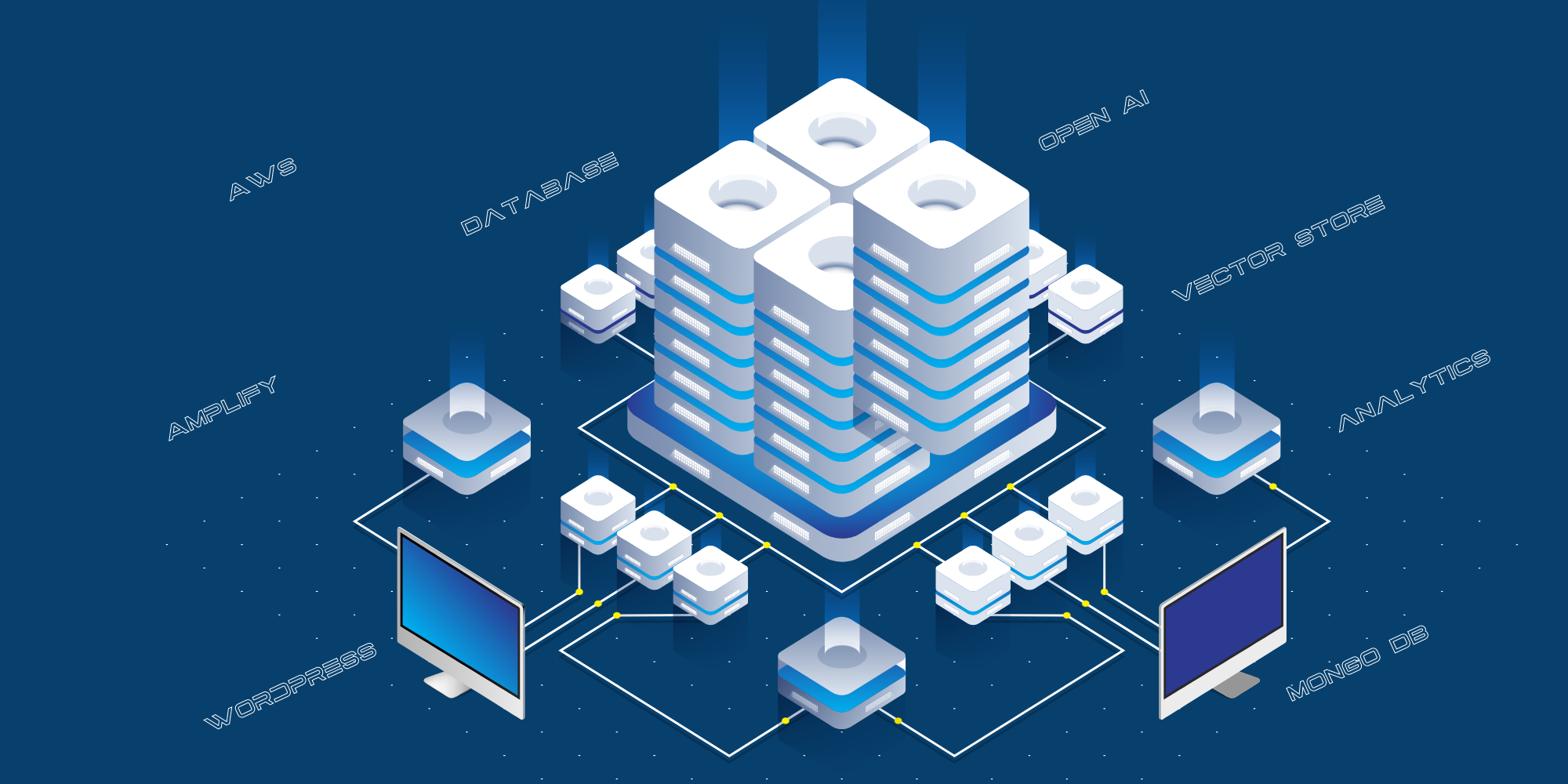
یہ موجودہ تکنیکی نفاذ ہے:
- صارفین کا سامنا کرنے والی ویب سائٹ AWS Amplify پر ہوسٹ کی گئی ہے۔
- پبلک سائٹ اور اوپن AI کے درمیان انضمام ایک API پرت کے ذریعے کیا جاتا ہے، جو AWS پر Python API سرور کے طور پر ہوسٹ کیا جاتا ہے۔
- ہم عوام کی طرف سے پوچھے گئے تمام سوالات، چیٹ GPT کے ذریعے دیے گئے جوابات، اور ذرائع کے URLs کو ذخیرہ کرنے کے لیے MongoDB کو بطور لاگ استعمال کرتے ہیں۔
- ہم تربیت کے لیے اوپن اے آئی کو منتقل کرنے کے لیے بلاگ، یوٹیوب وغیرہ سے ڈیٹا کی ساخت کے لیے مختلف اسکرپٹس کا استعمال کرتے ہیں۔
- ہم آواز کے استفسارات کو متن میں تبدیل کرنے کے لیے React-Speech Recognition کا استعمال کرتے ہیں۔
- ہم ویب سائٹ کے ٹریفک کو ٹریک کرنے کے لیے گوگل تجزیات کا بھی استعمال کرتے ہیں۔
یہ نوٹ کرنا ضروری ہے کہ ہم دو معاون استعمال کرتے ہیں:
- سوالات کے جوابات دینے کے لیے ایک۔
- ایک میٹا ڈیٹا URLs حاصل کرنے کے لیے، بلاگ کے URLs جن میں جوابات کے نیچے ذرائع کو ظاہر کرنے کے لیے اصل مواد موجود ہے۔
آگے کیا؟
- تقریر سے متن میں بہتری
اسپیچ ٹو ٹیکسٹ کے لیے اوپن اے آئی کا وسپر ماڈل ری ایکٹ سے زیادہ درست ہے۔ یہ باکس سے باہر متعدد زبانوں کو بھی سپورٹ کرتا ہے اور یہ مخلوط زبان کی تقریر، لہجوں اور بولیوں کو سنبھالنے میں اچھا ہے۔ نتیجے کے طور پر، میں آنے والے مہینوں میں زیادہ تر ممکنہ طور پر اس کی طرف جاؤں گا۔ اس نے کہا کہ اسے ترتیب دینا زیادہ پیچیدہ ہے لہذا اس میں کچھ وقت لگ سکتا ہے۔ آپ کو ماڈل کو ہینڈل کرنے، انحصار کا انتظام کرنے کی ضرورت ہے (مثال کے طور پر، ازگر، لائبریریاں)، اور یہ یقینی بنانا ہوگا کہ آپ کے پاس موثر کارکردگی کے لیے کافی ہارڈ ویئر موجود ہے۔ نیز، Whisper براؤزرز میں براہ راست استعمال کے لیے ڈیزائن نہیں کیا گیا ہے۔ ویب ایپ بناتے وقت، آپ کو ٹرانسکرپشن کو سنبھالنے کے لیے بیک اینڈ سروس بنانے کی ضرورت ہوتی ہے جس سے پیچیدگی بڑھ جاتی ہے۔
- Fabrice AI اوتار
میں ایک Fabrice AI اوتار بنانا چاہتا ہوں جو میری طرح لگتا ہے اور آپ اس سے بات کر سکتے ہیں۔ میں نے D-iD کا جائزہ لیا لیکن اپنے مقاصد کے لیے یہ بہت مہنگا پایا۔ گیارہ لیبز صرف آواز کے لیے ہیں۔ سنتھیزیا بہت اچھا ہے لیکن فی الحال حقیقی وقت میں ویڈیوز نہیں بناتا۔ آخر میں میں نے زیادہ مناسب قیمتوں اور فعالیت کو دیکھتے ہوئے HeyGen استعمال کرنے کا فیصلہ کیا۔
مجھے شبہ ہے کہ کسی وقت اوپن اے آئی اپنا حل جاری کرے گا لہذا یہ کام بے سود رہا ہوگا۔ میں اس سے راضی ہوں اور جب اور اگر آتا ہے تو اوپن AI حل پر جاؤں گا۔ اس مرحلے پر اس پوری مشق کا مقصد یہ جاننا ہے کہ AI کے ساتھ کیا ممکن ہے اور اس جگہ کو بہتر طور پر سمجھنے میں میری مدد کرنے کے لیے کتنا کام درکار ہے۔
- حسب ضرورت ڈیش بورڈ
اس وقت، مجھے دن کے سوالات اور جوابات کا اقتباس حاصل کرنے کے لیے ایک MongoDB استفسار چلانے کی ضرورت ہے۔ میں ایک سادہ ڈیش بورڈ بنا رہا ہوں جہاں میں ہر زبان کے سوالات کی تعداد، تقریر سے متن کی درخواستوں کی تعداد وغیرہ کے بارے میں اقتباسات اور سادہ اعدادوشمار حاصل کر سکتا ہوں۔
- اضافی ڈیٹا ذرائع
ہم نے ابھی FJ Labs پورٹ فولیو کو Fabrice AI پر اپ لوڈ کیا ہے۔ اب آپ پوچھ سکتے ہیں کہ آیا کوئی کمپنی پورٹ فولیو کا حصہ ہے۔ Fabrice AI کمپنی کی مختصر تفصیل اور اس کی ویب سائٹ کے لنک کے ساتھ جواب دیتا ہے۔

Fabrice AI کو جتنے ذاتی سوالات مل رہے تھے ان کے جوابات اس کے پاس نہیں تھے، میں نے اپنی 50 ویں سالگرہ کی ویڈیو میں ہر اسپیکر کو دستی طور پر ٹیگ کرنے کے لیے وقت نکالا تاکہ اسے مطلوبہ مواد دیا جا سکے۔

نتیجہ
AI سے متعلق تمام چیزوں پر میں نے پچھلے بارہ مہینوں میں جتنے بھی کام کیے ہیں، ایسا لگتا ہے کہ ایک واضح عالمگیر نتیجہ نکلتا ہے: آپ جتنا زیادہ انتظار کریں گے، اتنا ہی سستا، آسان اور بہتر ہوتا جائے گا، اور اتنا ہی زیادہ امکان ہے کہ Open AI پیش کرے گا۔ یہ! اس دوران، اگر آپ کا کوئی سوال ہے تو مجھے بتائیں۔