

























Fabrice AI: текущая техническая реализация
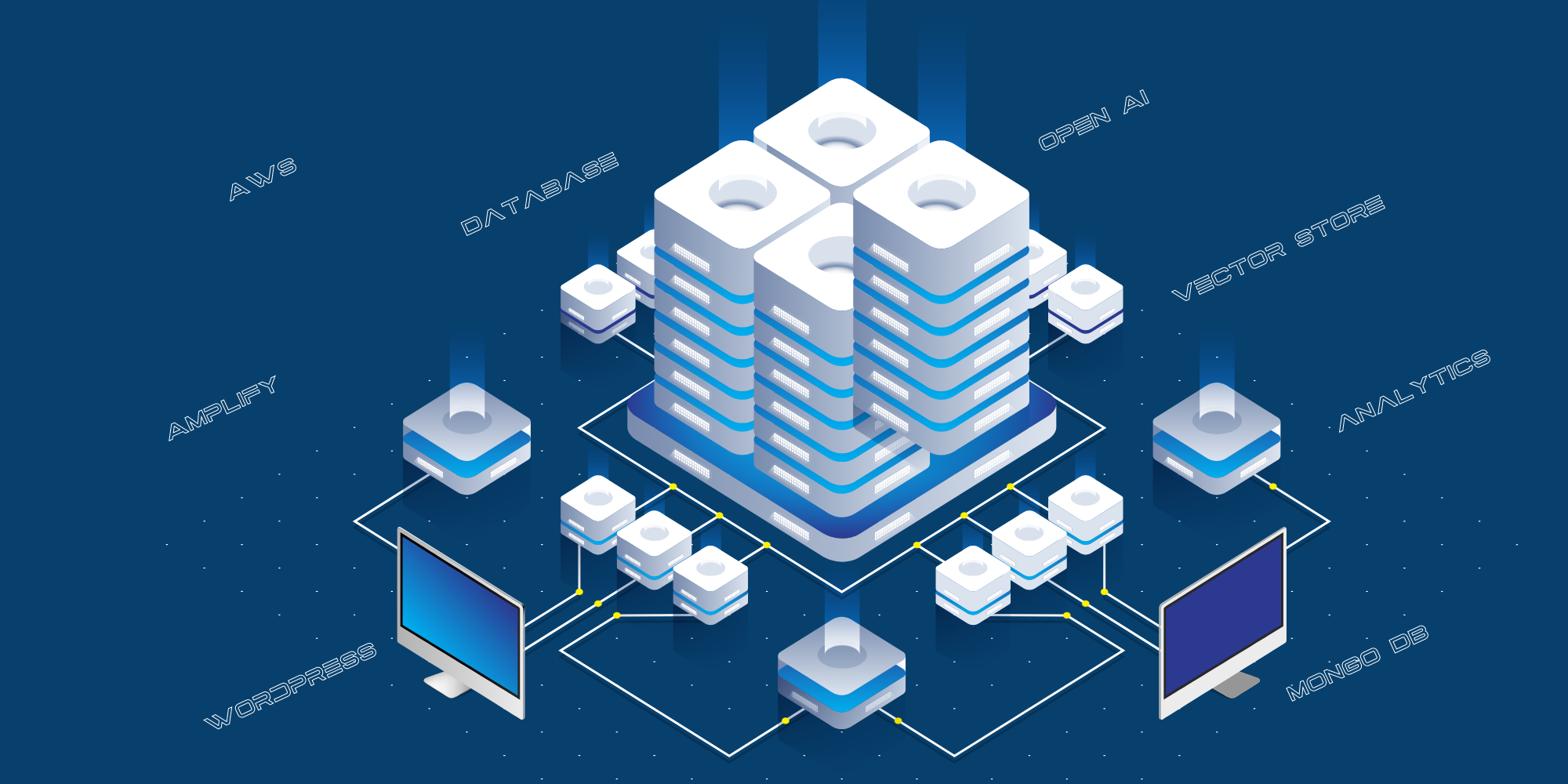
В последней заметке » Fabrice AI: Техническое путешествие» я рассказал о том, как мы прошли путь создания Fabrice AI, сделав полный круг. Я начал с использования Chat GPT 3 и 3.5. Разочаровавшись в результатах, я попытался использовать Langchain Framework для построения собственной модели ИИ поверх него, а затем вернулся к Chat GPT, когда они начали использовать векторные базы данных и значительно улучшили результаты с помощью 4o.
Вот текущий процесс обучения искусственного интеллекта Fabrice:
- Данные для обучения (записи в блогах, URL-адреса Youtube, URL-адреса подкастов, URL-адреса PDF и URL-адреса изображений) хранятся в нашей базе данных WordPress.
- Мы извлекаем данные и структурируем их.
- Мы предоставляем структурированные данные Open AI для обучения с помощью API Assistants.
- Затем Open AI создает базу данных векторного хранилища и сохраняет его.
Вот пример фрагмента структурированных данных. Каждый фрагмент контента имеет свой собственный JSON-файл. Мы следим за тем, чтобы не превысить лимит в 32 000 лексем.
{
«id»: «1»,
«date»: » «,
«link»: «https://fabricegrinda.com/»,
«title»: {
«rendered»: «Что такое искусственный интеллект Фабриса?»
},
«Категория»: «О Фабрисе»,
«featured_media»: «https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png»,
«other_media»: «»,
«knowledge_type»: «блог»,
«contentUpdated»: «Fabrice AI — это цифровое представление мыслей Фабриса, основанное на его записях в блоге и некоторых транскрибированных подкастах и интервью с помощью ChatGPT. Учитывая, что многие транскрипции несовершенны и что этот блог — лишь ограниченное представление Фабриса как личности, мы приносим извинения за неточности и недостающую информацию. Тем не менее, это хорошая отправная точка для ознакомления с мыслями Фабриса на многие темы.»
}
Это текущая техническая реализация:
- Сайт, ориентированный на потребителя, размещен на AWS Amplify.
- Интеграция между публичным сайтом и Open AI осуществляется через уровень API, который размещен на AWS в виде сервера Python API.
- Мы используем MongoDB в качестве журнала для хранения всех вопросов, заданных публикой, ответов, данных Chat GPT, и URL-адресов источников.
- Мы используем различные скрипты для структурирования данных из блога, YouTube и т.д., чтобы передать их в Open AI для обучения.
- Мы используем функцию распознавания речи React-Speech Recognition для преобразования голосовых запросов в текст.
- Мы также используем Google Analytics для отслеживания посещаемости сайта.
Важно отметить, что мы используем двух ассистентов:
- Один для ответов на вопросы.
- Один для получения URL метаданных, URL блогов, содержащих оригинальный контент, для отображения источников в нижней части ответов.
Что дальше?
- Улучшения преобразования речи в текст
Модель Whisper от Open AI для преобразования речи в текст более точна, чем React. Она также поддерживает несколько языков из коробки и хорошо справляется со смешанной речью, акцентами и диалектами. В результате я, скорее всего, перейду на нее в ближайшие месяцы. Тем не менее, он более сложен в настройке, так что это может занять некоторое время. Вам нужно работать с моделью, управлять зависимостями (например, Python, библиотеки) и убедиться, что у Вас достаточно оборудования для эффективной работы. Кроме того, Whisper не предназначен для прямого использования в браузерах. При создании веб-приложения Вам необходимо создать внутренний сервис для обработки транскрипции, что добавляет сложности.
- Аватар Фабриса ИИ
Я хочу создать ИИ-аватар Fabrice, который будет выглядеть и звучать как я, и с которым можно будет вести беседу. Я оценил D-iD, но решил, что он слишком дорог для моих целей. Eleven Labs работает только с голосом. Synthesia — замечательная программа, но в настоящее время она не создает видео в реальном времени. В итоге я решил использовать HeyGen, учитывая более подходящую цену и функциональность.
Я подозреваю, что в какой-то момент Open AI выпустит свое собственное решение, и тогда вся эта работа окажется напрасной. Я спокойно отношусь к этому и перейду на решение Open AI, когда и если оно появится. На данном этапе смысл всей этой работы заключается в том, чтобы узнать, что возможно с ИИ и сколько работы требуется, чтобы помочь мне лучше понять пространство.
- Пользовательская приборная панель
Сейчас мне нужно выполнить запрос к MongoDB, чтобы получить выдержку из вопросов и ответов за день. Я создаю простую приборную панель, на которой я смогу получать извлечения и простую статистику по количеству запросов на каждый язык, количеству запросов «речь в текст» и т.д.
- Дополнительные источники данных
Мы только что загрузили портфолио FJ Labs в Fabrice AI. Теперь Вы можете спросить, входит ли та или иная компания в портфолио. Fabrice AI ответит кратким описанием компании и ссылкой на ее сайт.

Учитывая количество личных вопросов, которые получал ИИ Fabrice и на которые у него не было ответов, я потратил время на то, чтобы вручную пометить каждого говорящего в моем видеоролике, посвященном 50-летию , чтобы дать ему необходимый контент.

Заключение
Учитывая всю ту работу, которую я проделал за последние двенадцать месяцев по всем вопросам, связанным с искусственным интеллектом, можно сделать однозначный вывод: чем больше Вы ждете, тем дешевле, проще и лучше все становится, и тем больше вероятность того, что Open AI предложит это! А пока дайте мне знать, если у Вас возникнут вопросы.