

























Fabrice AI: Obecna implementacja techniczna
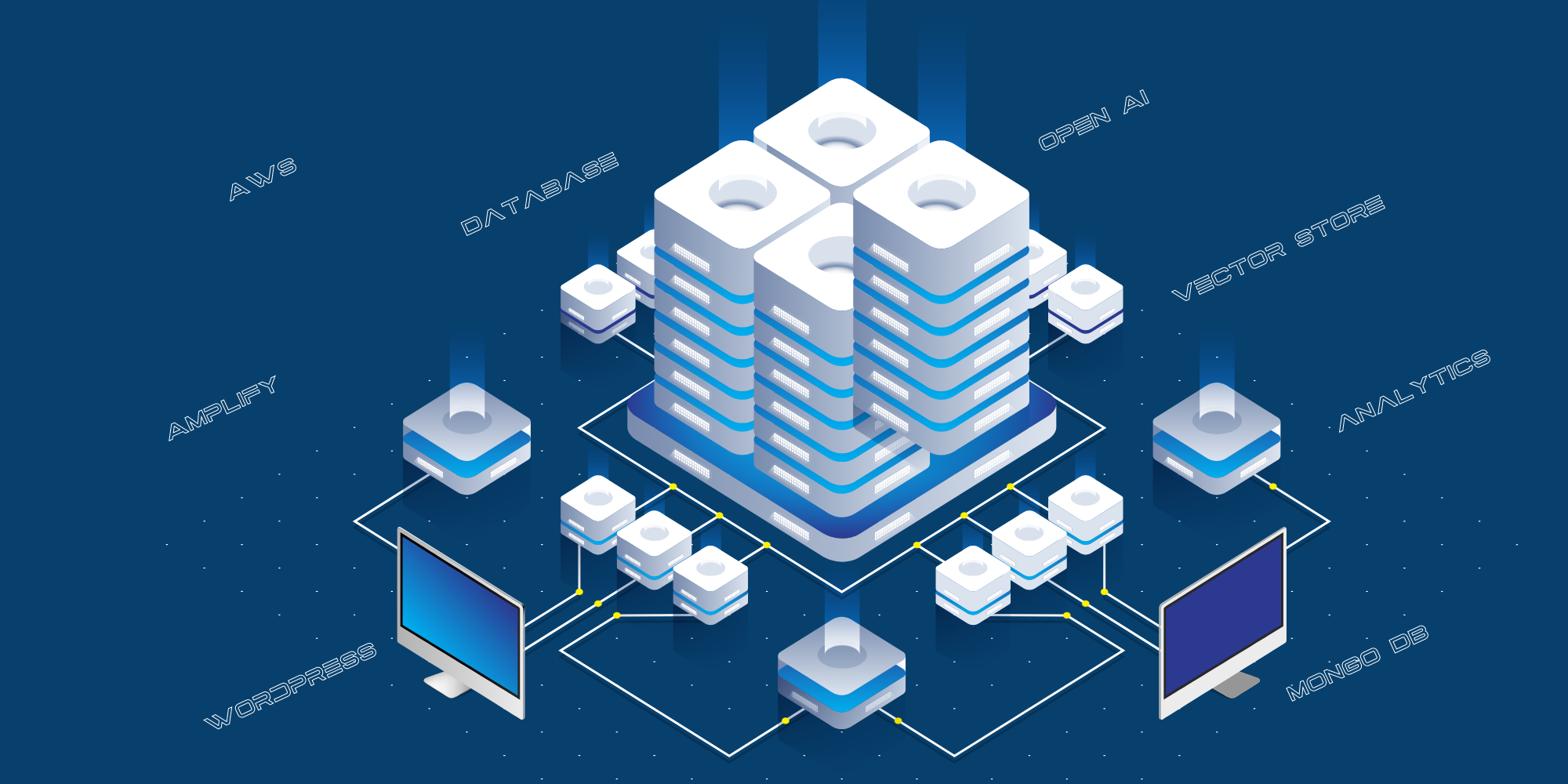
W ostatnim poście Fabrice AI: The Technical Journey wyjaśniłem drogę, jaką przeszliśmy, aby zbudować Fabrice AI, zataczając pełne koło. Zacząłem od korzystania z Chat GPT 3 i 3.5. Rozczarowany wynikami, próbowałem użyć Langchain Framework, aby zbudować na nim własny model sztucznej inteligencji, zanim wróciłem do Chat GPT, gdy zaczęli używać wektorowych baz danych i znacznie poprawili wyniki dzięki 4o.
Oto obecny proces szkolenia Fabrice AI:
- Dane szkoleniowe (posty na blogu, adresy URL Youtube, adresy URL podcastów, adresy URL plików PDF i adresy URL obrazów) są przechowywane w naszej bazie danych WordPress.
- Wyodrębniamy dane i nadajemy im strukturę.
- Dostarczamy ustrukturyzowane dane do Open AI w celu szkolenia za pomocą interfejsu API Assistants.
- Następnie Open AI tworzy wektorową bazę danych i przechowuje ją.
Oto przykład ustrukturyzowanych danych. Każda zawartość ma swój własny plik JSON. Dbamy o to, aby nie przekroczyć limitu 32 000 tokenów.
{
„id”: „1”,
„data”: ” „,
„link”: „https://fabricegrinda.com/”,
„title”: {
„renderowane”: „Czym jest Fabrice AI?”.
},
„Kategoria”: „O Fabrice”,
„featured_media”: „https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
„other_media”: „”,
„knowledge_type”: „blog”,
„contentUpdated”: „Fabrice AI to cyfrowa reprezentacja myśli Fabrice’a oparta na jego wpisach na blogu i wybranych transkrybowanych podcastach i wywiadach przy użyciu ChatGPT.Biorąc pod uwagę, że wiele transkrypcji jest niedoskonale przepisanych i że blog jest tylko ograniczoną reprezentacją Fabrice’a jako osoby, przepraszamy za nieścisłości i brakujące informacje. Niemniej jednak jest to dobry punkt wyjścia do zapoznania się z przemyśleniami Fabrice’a na wiele tematów”.
}
Jest to obecna implementacja techniczna:
- Strona internetowa skierowana do konsumentów jest hostowana w AWS Amplify.
- Integracja między witryną publiczną a Open AI odbywa się za pośrednictwem warstwy API, która jest hostowana w AWS jako serwer Python API.
- Używamy MongoDB jako dziennika do przechowywania wszystkich pytań zadawanych publicznie, odpowiedzi udzielonych przez Chat GPT oraz adresów URL źródeł.
- Używamy różnych skryptów do strukturyzowania danych z bloga, YouTube itp. w celu przekazania ich do Open AI w celu szkolenia.
- Używamy React-Speech Recognition do konwersji zapytań głosowych na tekst.
- Używamy również Google Analytics do śledzenia ruchu w witrynie.
Warto zauważyć, że korzystamy z dwóch asystentów:
- Jeden do odpowiadania na pytania.
- Jeden do pobierania adresów URL metadanych, adresów URL blogów, które mają oryginalną zawartość do wyświetlania źródeł na dole odpowiedzi.
Co dalej?
- Ulepszenia zamiany mowy na tekst
Model Whisper firmy Open AI do zamiany mowy na tekst jest dokładniejszy niż React. Obsługuje również wiele języków od razu po wyjęciu z pudełka i dobrze radzi sobie z mową w różnych językach, akcentami i dialektami. W rezultacie najprawdopodobniej przejdę na niego w nadchodzących miesiącach. Konfiguracja jest jednak bardziej złożona, więc może to trochę potrwać. Trzeba obsłużyć model, zarządzać zależnościami (np. Python, biblioteki) i upewnić się, że masz wystarczającą ilość sprzętu do wydajnej pracy. Ponadto Whisper nie jest przeznaczony do bezpośredniego użytku w przeglądarkach. Podczas tworzenia aplikacji internetowej należy utworzyć usługę zaplecza do obsługi transkrypcji, co zwiększa złożoność.
- Awatar Fabrice AI
Chcę stworzyć awatara Fabrice AI, który wygląda i brzmi jak ja, z którym można prowadzić rozmowę. Oceniłem D-iD, ale okazało się, że jest zbyt drogie dla moich celów. Eleven Labs obsługuje tylko głos. Synthesia jest świetna, ale obecnie nie tworzy filmów w czasie rzeczywistym. Ostatecznie zdecydowałem się na HeyGen, biorąc pod uwagę bardziej odpowiednią cenę i funkcjonalność.
Podejrzewam, że w pewnym momencie Open AI wyda własne rozwiązanie, więc ta praca pójdzie na marne. Czuję się z tym komfortowo i przejdę na rozwiązanie Open AI, kiedy i jeśli się pojawi. Na tym etapie celem tego całego ćwiczenia jest nauczenie się, co jest możliwe dzięki sztucznej inteligencji i ile pracy wymaga, aby pomóc mi lepiej zrozumieć tę przestrzeń.
- Niestandardowy pulpit nawigacyjny
Obecnie muszę uruchomić zapytanie MongoDB, aby uzyskać wyciąg z pytań i odpowiedzi z danego dnia. Buduję prosty pulpit nawigacyjny, w którym mogę uzyskać wyciągi i proste statystyki dotyczące liczby zapytań w poszczególnych językach, liczby żądań zamiany mowy na tekst itp.
- Dodatkowe źródła danych
Właśnie przesłaliśmy portfolio FJ Labs do Fabrice AI. Możesz teraz zapytać, czy firma jest częścią portfolio. Fabrice AI odpowie krótkim opisem firmy i linkiem do jej strony internetowej.

Biorąc pod uwagę liczbę osobistych pytań, na które Fabrice AI nie znała odpowiedzi, poświęciłem czas na ręczne oznaczenie każdego mówcy w moim 50th Birthday Video, aby zapewnić mu potrzebną treść.

Wnioski
Biorąc pod uwagę całą pracę, jaką wykonałem w ciągu ostatnich dwunastu miesięcy nad wszystkimi rzeczami związanymi ze sztuczną inteligencją, wydaje się, że istnieje jasny, uniwersalny wniosek: im dłużej czekasz, tym tańsze, łatwiejsze i lepsze staje się to i tym bardziej prawdopodobne, że Open AI to zaoferuje! W międzyczasie daj mi znać, jeśli masz jakieś pytania.