

























Fabrice AI: Attuale implementazione tecnica
Nell’ultimo post, Fabrice AI: il viaggio tecnico, ho spiegato il percorso che abbiamo seguito per costruire Fabrice AI facendo un giro completo. Ho iniziato usando le Chat GPT 3 e 3.5. Deluso dai risultati, ho provato a utilizzare Langchain Framework per costruire il mio modello di intelligenza artificiale, prima di tornare a Chat GPT quando ha iniziato a utilizzare i database vettoriali e a migliorare notevolmente i risultati con 4o.
Ecco l’attuale processo di formazione dell’intelligenza artificiale di Fabrice:
- I dati di formazione (post di blog, URL di Youtube, URL di podcast, URL di PDF e URL di immagini) sono archiviati nel nostro database WordPress.
- Estraiamo i dati e li strutturiamo.
- Forniamo i dati strutturati a Open AI per la formazione utilizzando l’API Assistants.
- Open AI crea quindi un database di archivi vettoriali e lo memorizza.
Ecco un esempio di dati strutturati. Ogni contenuto ha il suo file JSON. Ci assicuriamo di non superare il limite di 32.000 gettoni.
{
“id”: “1”,
“data”: ” “,
“link”: “https://fabricegrinda.com/”,
“titolo”: {
“reso”: “Che cos’è Fabrice AI?”
},
“Categoria”: “Informazioni su Fabrice”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“altri_media”: “”,
“tipo_di_conoscenza”: “blog”,
“contentUpdated”: “Fabrice AI è una rappresentazione digitale dei pensieri di Fabrice basata sui post del suo blog e su alcuni podcast e interviste trascritte con ChatGPT. Dato che molte delle trascrizioni sono imperfette e che il blog non è che una rappresentazione limitata di Fabrice come individuo, ci scusiamo per le imprecisioni e le informazioni mancanti. Tuttavia, questo è un buon punto di partenza per conoscere i pensieri di Fabrice su molti argomenti”.
}
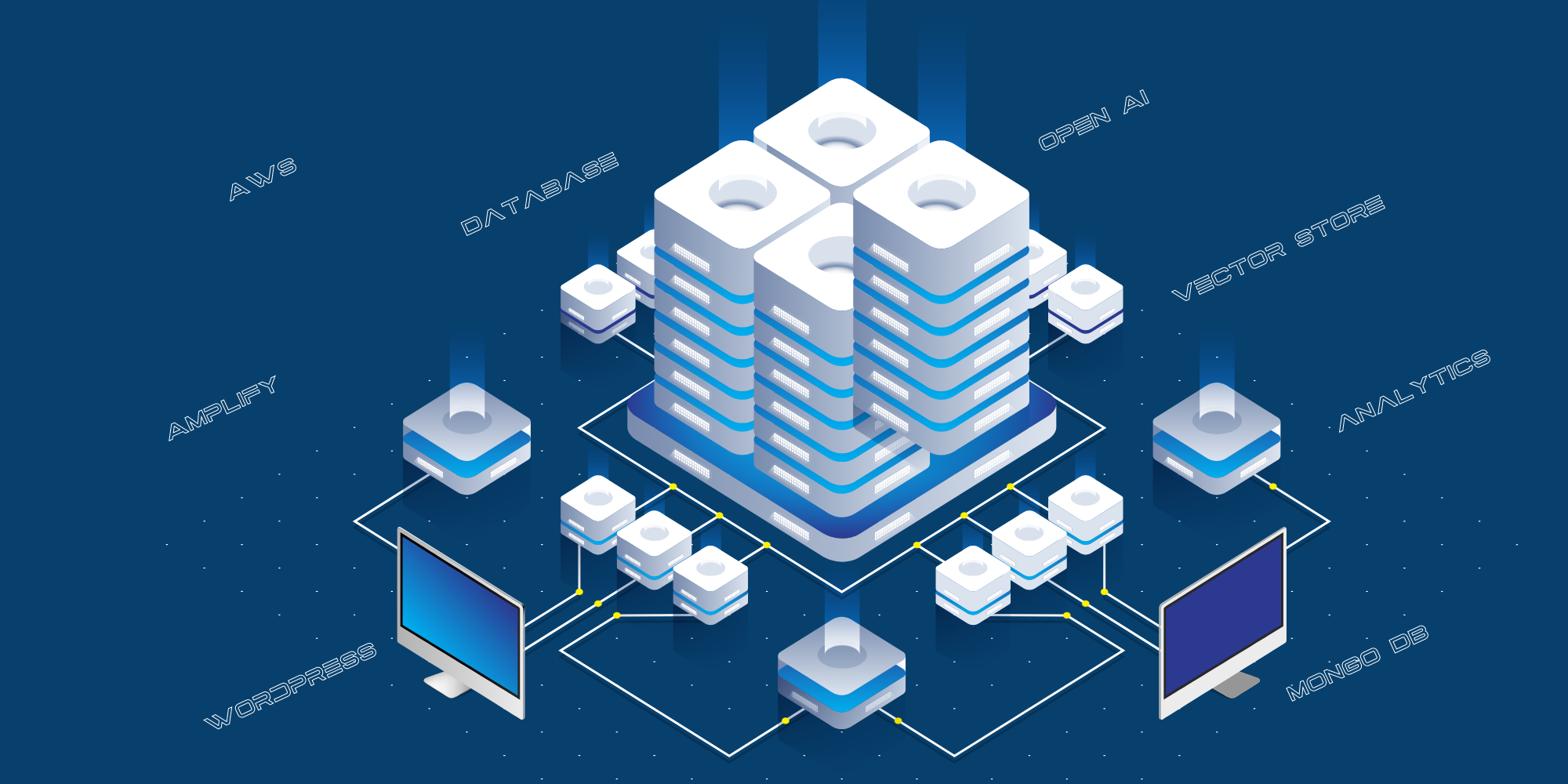
Questa è l’attuale implementazione tecnica:
- Il sito web rivolto ai consumatori è ospitato su AWS Amplify.
- L’integrazione tra il sito pubblico e Open AI avviene attraverso un livello API, ospitato su AWS come server API Python.
- Utilizziamo MongoDB come registro per memorizzare tutte le domande poste dal pubblico, le risposte fornite dalla Chat GPT e gli URL delle fonti.
- Utilizziamo vari script per strutturare i dati provenienti dal blog, da YouTube, ecc. da passare a Open AI per l’addestramento.
- Utilizziamo React-Speech Recognition per convertire le richieste vocali in testo.
- Utilizziamo anche Google Analytics per monitorare il traffico del sito web.
È importante notare che utilizziamo due assistenti:
- Uno per rispondere alle domande.
- Uno per ottenere gli URL dei metadati, ovvero gli URL dei blog che hanno il contenuto originale per visualizzare le fonti in fondo alle risposte.
E poi?
- Miglioramenti al linguaggio parlato
Il modello Whisper di Open AI per la sintesi vocale è più preciso di React. Inoltre, supporta più lingue ed è in grado di gestire discorsi in lingue miste, accenti e dialetti. Di conseguenza, molto probabilmente passerò a questo modello nei prossimi mesi. Tuttavia è più complesso da configurare, quindi potrebbe volerci un po’ di tempo. Devi gestire il modello, gestire le dipendenze (ad esempio, Python, librerie) e assicurarti di avere un hardware sufficiente per ottenere prestazioni efficienti. Inoltre, Whisper non è stato progettato per essere utilizzato direttamente nei browser. Quando costruisci un’applicazione web, devi creare un servizio backend per gestire la trascrizione, il che aggiunge complessità.
- Fabrice AI Avatar
Voglio creare un avatar Fabrice AI che abbia il mio stesso aspetto e la mia stessa voce e con il quale sia possibile conversare. Ho valutato D-iD ma l’ho trovato troppo costoso per i miei scopi. Eleven Labs è solo vocale. Synthesia è ottimo ma al momento non crea video in tempo reale. Alla fine ho deciso di utilizzare HeyGen, visto il prezzo e le funzionalità più adeguate.
Sospetto che a un certo punto Open AI rilascerà la propria soluzione e che questo lavoro sarà stato inutile. Sono tranquillo e passerò alla soluzione di Open AI quando e se verrà rilasciata. A questo punto lo scopo di tutto questo esercizio è imparare cosa è possibile fare con l’IA e quanto lavoro richiede per aiutarmi a capire meglio lo spazio.
- Cruscotto personalizzato
In questo momento, ho bisogno di eseguire una query MongoDB per ottenere un estratto delle domande e delle risposte del giorno. Sto costruendo una semplice dashboard dove posso ottenere estrazioni e semplici statistiche sul numero di interrogazioni per lingua, sul numero di richieste speech-to-text, ecc.
- Fonti di dati aggiuntive
Abbiamo appena caricato il Portfolio di FJ Labs su Fabrice AI. Ora puoi chiedere se un’azienda fa parte del portfolio. Fabrice AI risponde con una breve descrizione dell’azienda e un link al suo sito web.

Dato il numero di domande personali che l’intelligenza artificiale di Fabrice riceveva e alle quali non sapeva rispondere, mi sono preso il tempo di etichettare manualmente ogni interlocutore del mio video del 50° compleanno per dargli il contenuto di cui aveva bisogno.

Conclusione
Con tutto il lavoro che ho svolto negli ultimi dodici mesi su tutto ciò che riguarda l’IA, sembra esserci una chiara conclusione universale: più aspetti, più diventa economico, facile e migliore e più è probabile che Open AI lo offra! Nel frattempo, fammi sapere se hai domande.