

























फैब्रिस एआई: वर्तमान तकनीकी कार्यान्वयन
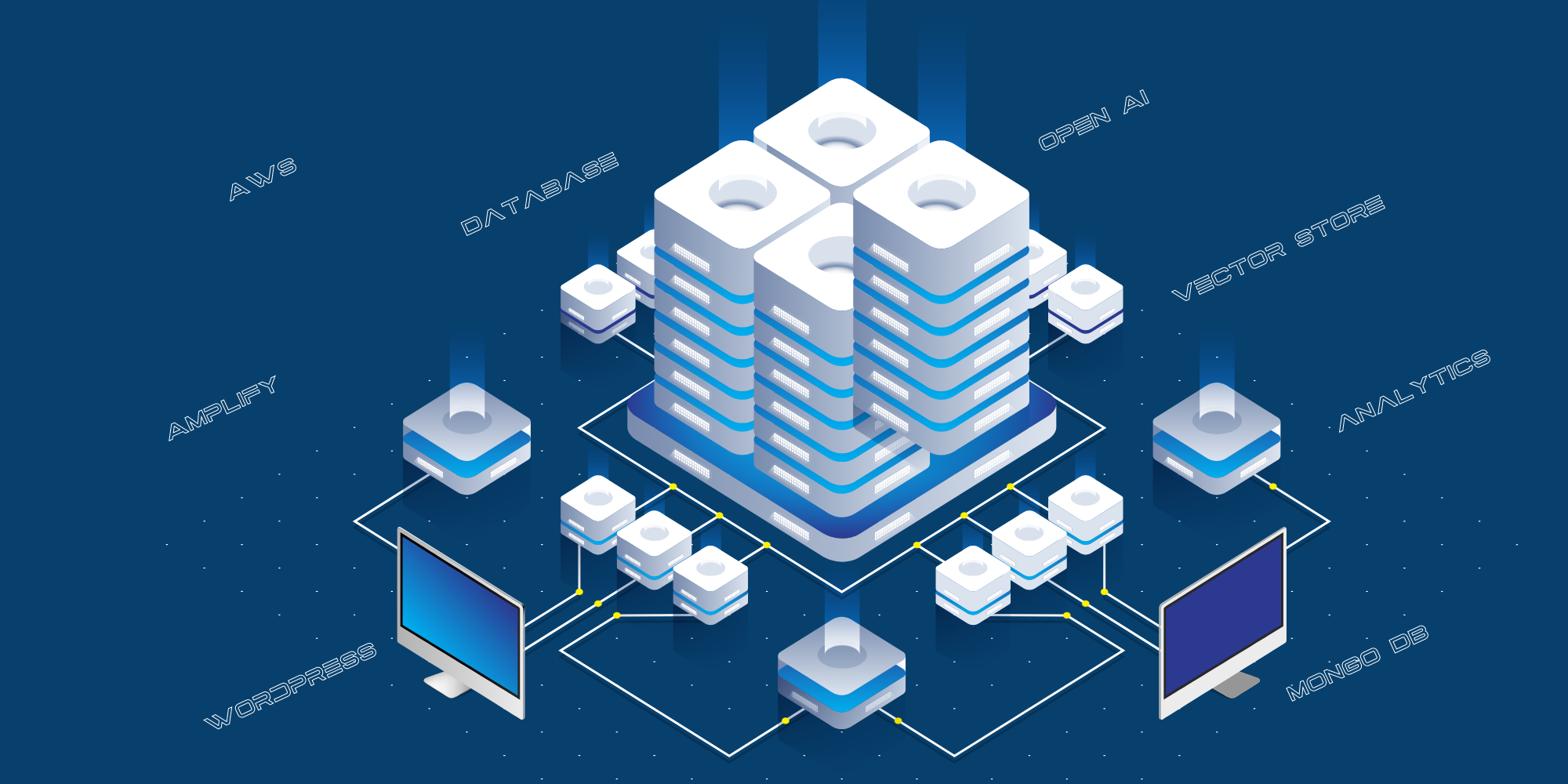
पिछली पोस्ट, फैब्रिस एआई: द टेक्निकल जर्नी में मैंने फैब्रिस एआई के निर्माण की यात्रा के बारे में बताया था। मैंने चैट जीपीटी 3 और 3.5 का उपयोग करके शुरुआत की। परिणामों से निराश होकर, मैंने चैट जीपीटी पर अपना खुद का एआई मॉडल बनाने के लिए लैंगचेन फ्रेमवर्क का उपयोग करने की कोशिश की, जब उन्होंने वेक्टर डेटाबेस का उपयोग करना शुरू किया और 4o के साथ परिणामों में बड़े पैमाने पर सुधार किया।
फैब्रिस एआई के प्रशिक्षण की वर्तमान प्रक्रिया इस प्रकार है:
- प्रशिक्षण डेटा (ब्लॉग पोस्ट, यूट्यूब यूआरएल, पॉडकास्ट यूआरएल, पीडीएफ यूआरएल और छवि यूआरएल) हमारे वर्डप्रेस डेटाबेस में संग्रहीत है।
- हम डेटा निकालते हैं और उसे संरचित करते हैं।
- हम सहायक एपीआई का उपयोग करके प्रशिक्षण के लिए ओपन एआई को संरचित डेटा प्रदान करते हैं।
- इसके बाद ओपन एआई एक वेक्टर स्टोर डेटाबेस बनाता है और उसे संग्रहीत करता है।
यहाँ संरचित डेटा के एक टुकड़े का उदाहरण दिया गया है। प्रत्येक सामग्री की अपनी JSON फ़ाइल होती है। हम यह सुनिश्चित करते हैं कि टोकन की सीमा 32,000 से अधिक न हो।
{
“आईडी”: “1”,
“तारीख”: ” “,
“लिंक”:”https://fabricegrind.com/”,
“शीर्षक”: {
“rendered”: “फैब्रिस एआई क्या है?”
},
“श्रेणी”: “फैब्रिस के बारे में”,
“featured_media”: “https://fabricegrind.com/wp-content/uploads/2023/12/About-me.png”,
“अन्य_मीडिया”: “”,
“ज्ञान_प्रकार”: “ब्लॉग”,
“contentUpdated”: “फैब्रिस एआई फैब्रिस के विचारों का डिजिटल प्रतिनिधित्व है जो उनके ब्लॉग पोस्ट और चुनिंदा ट्रांसक्राइब किए गए पॉडकास्ट और चैटजीपीटी का उपयोग करके साक्षात्कारों पर आधारित है। यह देखते हुए कि कई ट्रांसक्रिप्शन अपूर्ण रूप से ट्रांसक्राइब किए गए हैं और ब्लॉग फैब्रिस के व्यक्तित्व का सीमित प्रतिनिधित्व है, हम गलतियों और गुम जानकारी के लिए क्षमा चाहते हैं। फिर भी, यह कई विषयों पर फैब्रिस के विचारों को जानने के लिए एक अच्छा प्रारंभिक बिंदु है।”
}
वर्तमान तकनीकी कार्यान्वयन इस प्रकार है:
- उपभोक्ता-उन्मुख वेबसाइट AWS एम्पलीफाई पर होस्ट की गई है।
- सार्वजनिक साइट और ओपन एआई के बीच एकीकरण एक एपीआई परत के माध्यम से किया जाता है, जिसे AWS पर पायथन एपीआई सर्वर के रूप में होस्ट किया जाता है।
- हम जनता द्वारा पूछे गए सभी प्रश्नों, चैट GPT द्वारा दिए गए उत्तरों और स्रोतों के URL को संग्रहीत करने के लिए MongoDB को लॉग के रूप में उपयोग करते हैं।
- हम ब्लॉग, यूट्यूब आदि से डेटा को संरचित करने के लिए विभिन्न स्क्रिप्ट का उपयोग करते हैं, ताकि उसे प्रशिक्षण के लिए ओपन एआई को भेजा जा सके।
- हम ध्वनि पूछताछ को पाठ में परिवर्तित करने के लिए रिएक्ट-स्पीच रिकॉग्निशन का उपयोग करते हैं।
- हम वेबसाइट ट्रैफ़िक को ट्रैक करने के लिए गूगल एनालिटिक्स का भी उपयोग करते हैं।
यह ध्यान रखना महत्वपूर्ण है कि हम दो सहायकों का उपयोग करते हैं:
- एक प्रश्नों के उत्तर देने के लिए।
- एक मेटाडेटा यूआरएल प्राप्त करने के लिए, ब्लॉग यूआरएल जिसमें मूल सामग्री होती है ताकि उत्तरों के नीचे स्रोत प्रदर्शित हो सके।
आगे क्या?
- भाषण-से-पाठ सुधार
स्पीच टू टेक्स्ट के लिए ओपन एआई का व्हिस्पर मॉडल रिएक्ट से ज़्यादा सटीक है। यह बॉक्स से बाहर कई भाषाओं का भी समर्थन करता है और यह मिश्रित भाषा के भाषण, लहजे और बोलियों को संभालने में अच्छा है। नतीजतन, मैं आने वाले महीनों में सबसे अधिक संभावना इसे अपनाने जा रहा हूँ। कहा जाता है कि इसे सेट अप करना ज़्यादा जटिल है, इसलिए इसमें कुछ समय लग सकता है। आपको मॉडल को संभालने, निर्भरताओं (जैसे, पायथन, लाइब्रेरी) को प्रबंधित करने और यह सुनिश्चित करने की ज़रूरत है कि आपके पास कुशल प्रदर्शन के लिए पर्याप्त हार्डवेयर है। साथ ही, व्हिस्पर को ब्राउज़र में सीधे इस्तेमाल के लिए डिज़ाइन नहीं किया गया है। वेब ऐप बनाते समय, आपको ट्रांसक्रिप्शन को संभालने के लिए एक बैकएंड सेवा बनाने की ज़रूरत होती है जो जटिलता को बढ़ाती है।
- फैब्रिस एआई अवतार
मैं एक फैब्रिस एआई अवतार बनाना चाहता हूँ जो दिखने और बोलने में मेरे जैसा हो और जिससे आप बातचीत कर सकें। मैंने D-iD का मूल्यांकन किया लेकिन पाया कि यह मेरे उद्देश्यों के लिए बहुत महंगा है। इलेवन लैब्स केवल आवाज़ के लिए है। सिंथेसिया बढ़िया है लेकिन वर्तमान में वास्तविक समय में वीडियो नहीं बनाता है। अंत में मैंने अधिक उचित मूल्य और कार्यक्षमता को देखते हुए हेजेन का उपयोग करने का निर्णय लिया।
मुझे संदेह है कि किसी समय ओपन एआई अपना समाधान जारी करेगा, इसलिए यह काम व्यर्थ हो जाएगा। मैं इससे सहज हूं और जब ओपन एआई समाधान आएगा तो मैं उस पर स्विच करूंगा। इस स्तर पर इस पूरी कवायद का उद्देश्य यह जानना है कि एआई के साथ क्या संभव है और इस क्षेत्र को बेहतर ढंग से समझने में मेरी मदद करने के लिए कितना काम करना होगा।
- कस्टम डैशबोर्ड
अभी, मुझे दिन भर के प्रश्नों और उत्तरों का सार प्राप्त करने के लिए MongoDB क्वेरी चलाने की आवश्यकता है। मैं एक सरल डैशबोर्ड बना रहा हूँ जहाँ मैं प्रति भाषा क्वेरी की संख्या, स्पीच-टू-टेक्स्ट अनुरोधों की संख्या आदि पर सार और सरल आँकड़े प्राप्त कर सकता हूँ।
- अतिरिक्त डेटा स्रोत
हमने अभी FJ Labs पोर्टफोलियो को Fabrice AI पर अपलोड किया है। अब आप पूछ सकते हैं कि क्या कोई कंपनी पोर्टफोलियो का हिस्सा है। Fabrice AI कंपनी का संक्षिप्त विवरण और उसकी वेबसाइट का लिंक देकर जवाब देता है।

फैब्रिस एआई को बहुत से व्यक्तिगत प्रश्न मिल रहे थे, जिनके उत्तर उसके पास नहीं थे, इसलिए मैंने अपने 50 वें जन्मदिन के वीडियो में प्रत्येक वक्ता को मैन्युअल रूप से टैग करने में समय लगाया, ताकि उसे आवश्यक सामग्री दी जा सके।

निष्कर्ष
पिछले बारह महीनों में मैंने AI से जुड़ी सभी चीज़ों पर जो काम किया है, उससे एक स्पष्ट सार्वभौमिक निष्कर्ष निकलता है: जितना ज़्यादा आप इंतज़ार करेंगे, यह उतना ही सस्ता, आसान और बेहतर होगा, और उतनी ही ज़्यादा संभावना है कि Open AI इसे पेश करेगा! इस बीच, अगर आपके कोई सवाल हों तो मुझे बताएँ।