

























Fabrice AI: Implementación técnica actual
En el último post, Fabrice AI: El viaje técnico expliqué el viaje que hicimos para construir Fabrice AI haciendo un círculo completo. Empecé utilizando Chat GPT 3 y 3.5. Decepcionado con los resultados, intenté utilizar el Marco Langchain para construir mi propio modelo de IA sobre él, antes de volver a Chat GPT una vez que empezaron a utilizar bases de datos vectoriales y a mejorar masivamente los resultados con 4o.
Éste es el proceso actual para entrenar a Fabrice AI:
- Los datos de entrenamiento (entradas de blog, URL de Youtube, URL de podcasts, URL de PDF y URL de imágenes) se almacenan en nuestra base de datos de WordPress.
- Extraemos los datos y los estructuramos.
- Proporcionamos los datos estructurados a Open AI para su entrenamiento mediante la API de Asistentes.
- Open AI crea entonces una base de datos de almacén vectorial y la almacena.
Aquí tienes un ejemplo de dato estructurado. Cada contenido tiene su propio archivo JSON. Nos aseguramos de no superar el límite de 32.000 tokens.
{
«id»: «1»,
«fecha»: » «,
«enlace»: «https://fabricegrinda.com/»,
«título»: {
«renderizado»: «¿Qué es Fabrice AI?»
},
«Categoría»: «Sobre Fabrice»,
«featured_media»: «https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png»,
«otros_medios»: «»,
«tipo_conocimiento»: «blog»,
«contenidoActualizado»: «Fabrice AI es una representación digital de los pensamientos de Fabrice basada en las entradas de su blog y en podcasts y entrevistas seleccionadas transcritas mediante ChatGPT.Dado que muchas de las transcripciones están imperfectamente transcritas y que el blog no es más que una representación limitada de Fabrice como individuo, pedimos disculpas por las inexactitudes y la información que falta. No obstante, es un buen punto de partida para conocer las opiniones de Fabrice sobre muchos temas.»
}
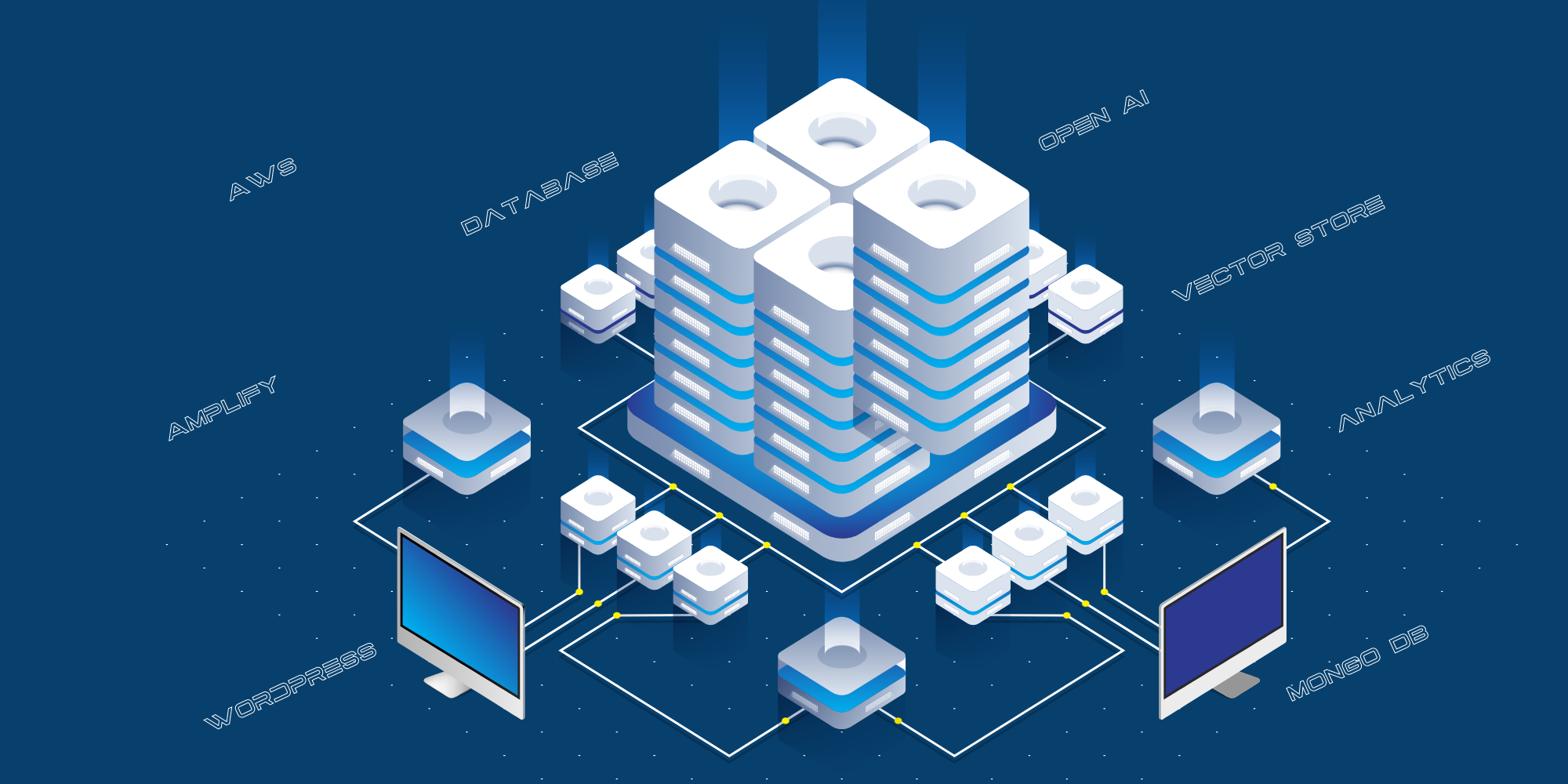
Esta es la implementación técnica actual:
- El sitio web orientado al consumidor está alojado en AWS Amplify.
- La integración entre el sitio público y Open AI se realiza a través de una capa API, que está alojada en AWS como servidor API Python.
- Utilizamos MongoDB como registro para almacenar todas las preguntas formuladas por el público, las respuestas dadas por Chat GPT y las URL de las fuentes.
- Utilizamos varios scripts para estructurar los datos del blog, YouTube, etc. para pasarlos a Open AI para el entrenamiento.
- Utilizamos el reconocimiento de voz React para convertir las consultas de voz en texto.
- También utilizamos Google Analytics para hacer un seguimiento del tráfico del sitio web.
Es importante señalar que utilizamos dos ayudantes:
- Uno para responder preguntas.
- Uno para obtener las URL de los metadatos, las URL de los blogs que tienen el contenido original para mostrar las fuentes en la parte inferior de las respuestas.
¿Y ahora qué?
- Mejoras en la conversión de voz a texto
El modelo Whisper de Open AI para convertir voz en texto es más preciso que React. Además, es compatible con varios idiomas y maneja bien el habla mixta, los acentos y los dialectos. Por ello, lo más probable es que me pase a él en los próximos meses. Dicho esto, es más complejo de configurar, así que puede que tarde un poco. Tienes que manejar el modelo, gestionar las dependencias (por ejemplo, Python, bibliotecas) y asegurarte de que tienes suficiente hardware para un rendimiento eficaz. Además, Whisper no está diseñado para su uso directo en navegadores. Cuando construyes una aplicación web, necesitas crear un servicio backend para gestionar la transcripción, lo que añade complejidad.
- Avatar de Fabrice AI
Quiero crear un Avatar Fabrice AI que se parezca y suene como yo y con el que puedas mantener una conversación. Evalué D-iD, pero me pareció demasiado caro para mis propósitos. Eleven Labs es sólo voz. Synthesia es genial, pero actualmente no crea vídeos en tiempo real. Al final decidí utilizar HeyGen por su precio y funcionalidad más adecuados.
Sospecho que en algún momento Open AI lanzará su propia solución, por lo que este trabajo habrá sido en vano. Me siento cómodo con ello y cambiaré a la solución de Open AI cuando llegue y si llega. En este momento, el objetivo de todo este ejercicio es aprender qué es posible con la IA y cuánto trabajo requiere para ayudarme a comprender mejor el espacio.
- Panel de control personalizado
En este momento, necesito ejecutar una consulta MongoDB para obtener un extracto de las preguntas y respuestas del día. Estoy construyendo un sencillo panel de control en el que puedo obtener extracciones y estadísticas sencillas sobre el número de consultas por idioma, el número de peticiones de voz a texto, etc.
- Fuentes de datos adicionales
Acabamos de subir la Cartera de FJ Labs a Fabrice AI. Ahora puedes preguntar si una empresa forma parte de la cartera. Fabrice AI responde con una breve descripción de la empresa y un enlace a su sitio web.

Dada la cantidad de preguntas personales que la IA de Fabrice recibía y para las que no tenía respuesta, me tomé la molestia de etiquetar manualmente a cada orador de mi Vídeo del 50 cumpleaños para darle el contenido que necesitaba.

Conclusión
Con todo el trabajo que he realizado en los últimos doce meses sobre todo lo relacionado con la IA, parece haber una clara conclusión universal: cuanto más esperes, más barato, fácil y mejor será, ¡y más probable será que la IA Abierta lo ofrezca! Mientras tanto, avísame si tienes alguna pregunta.