

























Fabrice AI: Nuværende teknisk implementering
I det sidste indlæg, Fabrice AI: The Technical Journey, forklarede jeg den rejse, vi gik igennem for at bygge Fabrice AI, og som var en fuld cirkel. Jeg startede med at bruge Chat GPT 3 og 3.5. Skuffet over resultaterne forsøgte jeg at bruge Langchain Framework til at bygge min egen AI-model oven på den, før jeg vendte tilbage til Chat GPT, da de begyndte at bruge vektordatabaser og massivt forbedrede resultaterne med 4o.
Her er den nuværende proces for træning af Fabrice AI:
- Træningsdataene (blogindlæg, Youtube-URL’er, podcast-URL’er, PDF-URL’er og billed-URL’er) er gemt i vores WordPress-database.
- Vi udtrækker data og strukturerer dem.
- Vi leverer de strukturerede data til Open AI til træning ved hjælp af Assistants API.
- Open AI opretter derefter en vektorlager-database og gemmer den.
Her er et eksempel på et stykke struktureret data. Hvert stykke indhold har sin egen JSON-fil. Vi sørger for ikke at overskride grænsen på 32.000 tokens.
{
“id”: “1”,
“dato”: ” “,
“link”:”https://fabricegrinda.com/”,
“title”: {
“gengivet”: “Hvad er Fabrice AI?”
},
“Kategori”: “Om Fabrice”,
“featured_media”: “https://fabricegrinda.com/wp-content/uploads/2023/12/About-me.png”,
“andre_medier”: “”,
“viden_type”: “blog”,
“contentUpdated”: “Fabrice AI er en digital repræsentation af Fabrices tanker baseret på hans blogindlæg og udvalgte transskriberede podcasts og interviews ved hjælp af ChatGPT. I betragtning af at mange af transskriptionerne er ufuldstændigt transskriberede, og at bloggen kun er en begrænset repræsentation af Fabrice som person, undskylder vi unøjagtigheder og manglende oplysninger. Ikke desto mindre er dette et godt udgangspunkt for at få Fabrices tanker om mange emner.”
}
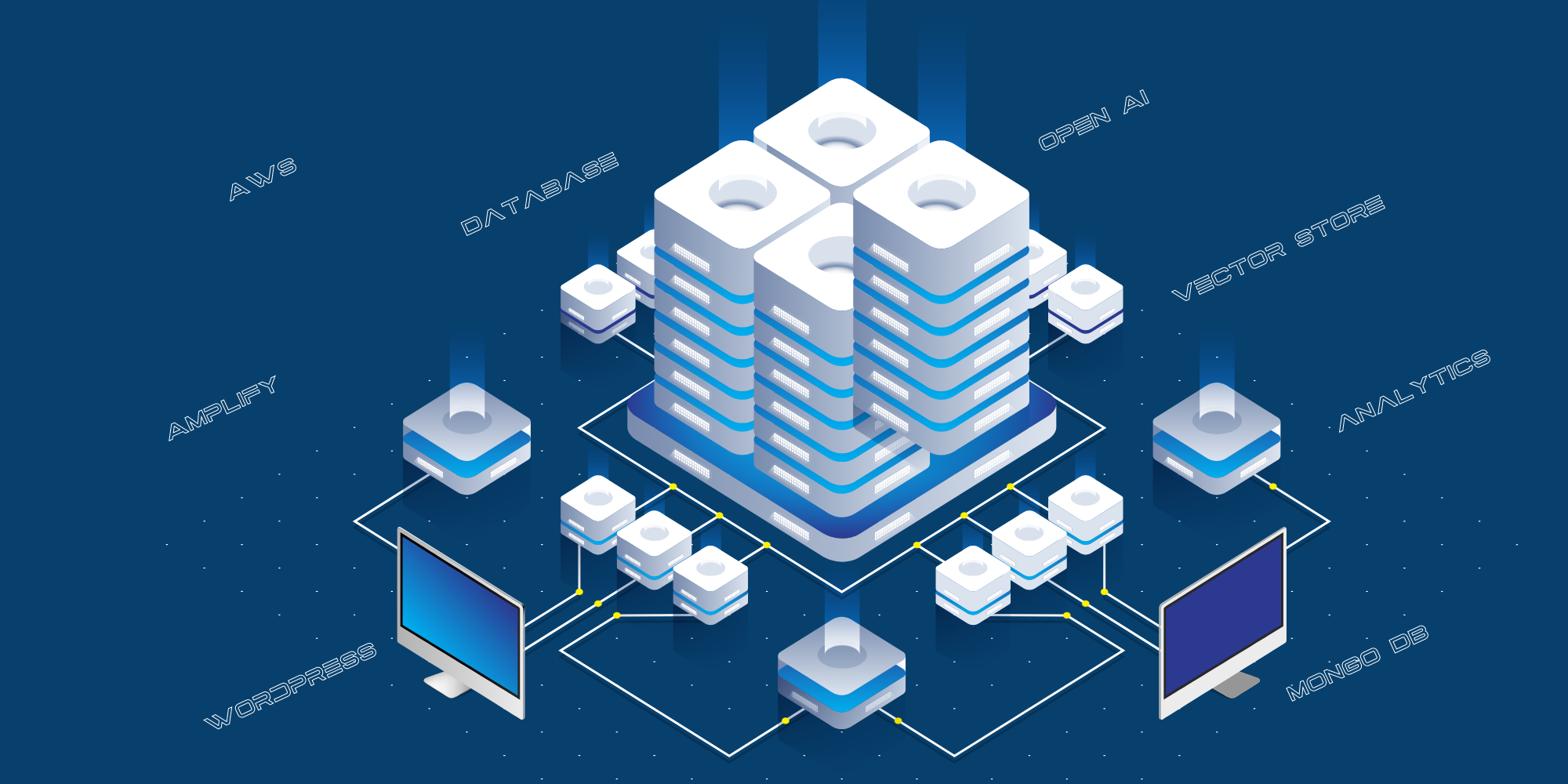
Det er den nuværende tekniske implementering:
- Den forbrugerrettede hjemmeside er hostet på AWS Amplify.
- Integrationen mellem det offentlige websted og Open AI sker via et API-lag, som hostes på AWS som en Python API-server.
- Vi bruger MongoDB som log til at gemme alle de spørgsmål, som offentligheden har stillet, de svar, som Chat GPT har givet, og kildernes URL’er.
- Vi bruger forskellige scripts til at strukturere data fra bloggen, YouTube osv. og sende dem til Open AI til træning.
- Vi bruger React-Speech Recognition til at konvertere stemmeforespørgsler til tekst.
- Vi bruger også Google Analytics til at spore trafikken på hjemmesiden.
Det er vigtigt at bemærke, at vi bruger to assistenter:
- En til at svare på spørgsmål.
- En til at hente metadata-URL’er, de blog-URL’er, der har det originale indhold, så kilderne kan vises nederst i svarene.
Hvad bliver det næste?
- Forbedringer af tale-til-tekst
Open AI’s Whisper-model til tale til tekst er mere præcis end React. Den understøtter også flere sprog fra start, og den er god til at håndtere tale på blandede sprog, accenter og dialekter. Derfor vil jeg højst sandsynligt gå over til den i de kommende måneder. Når det er sagt, er det mere komplekst at sætte op, så det kan tage et stykke tid. Du skal håndtere modellen, styre afhængigheder (f.eks. Python, biblioteker) og sikre, at du har tilstrækkelig hardware til effektiv ydelse. Whisper er heller ikke designet til direkte brug i browsere. Når du bygger en webapp, skal du oprette en backend-tjeneste til at håndtere transskriptionen, hvilket øger kompleksiteten.
- Fabrice AI Avatar
Jeg vil gerne skabe en Fabrice AI-avatar, der ser ud og lyder som mig, og som man kan føre en samtale med. Jeg vurderede D-iD, men fandt det alt for dyrt til mine formål. Eleven Labs er kun til stemmer. Synthesia er fantastisk, men kan i øjeblikket ikke lave videoer i realtid. I sidste ende besluttede jeg at bruge HeyGen på grund af den mere passende pris og funktionalitet.
Jeg formoder, at Open AI på et tidspunkt vil udgive sin egen løsning, så dette arbejde vil have været forgæves. Det har jeg det fint med, og jeg vil skifte til Open AI-løsningen, når og hvis den kommer. På nuværende tidspunkt er pointen med hele denne øvelse at lære, hvad der er muligt med AI, og hvor meget arbejde det kræver for at hjælpe mig med at forstå området bedre.
- Brugerdefineret dashboard
Lige nu har jeg brug for at køre en MongoDB-forespørgsel for at få et udtræk af dagens spørgsmål og svar. Jeg er ved at bygge et simpelt dashboard, hvor jeg kan få udtræk og simpel statistik over antallet af forespørgsler pr. sprog, antallet af tale-til-tekst-anmodninger osv.
- Yderligere datakilder
Vi har lige uploadet FJ Labs-porteføljen til Fabrice AI. Du kan nu spørge, om en virksomhed er en del af porteføljen. Fabrice AI svarer med en kort beskrivelse af virksomheden og et link til dens hjemmeside.

I betragtning af antallet af personlige spørgsmål, som Fabrice AI fik, og som den ikke havde svar på, tog jeg mig tid til manuelt at tagge hver taler i min 50-års fødselsdagsvideo for at give den det indhold, den havde brug for.

Konklusion
Med alt det arbejde, jeg har udført i løbet af de sidste tolv måneder om alt, hvad der har med AI at gøre, synes der at være en klar universel konklusion: Jo mere du venter, jo billigere, nemmere og bedre bliver det, og jo mere sandsynligt er det, at Open AI vil tilbyde det! I mellemtiden må du endelig sige til, hvis du har spørgsmål.
