I had a fun and wide ranging conversation with my cousin Minter Dial who is an amazing author, speaker, conversationalist, and fellow padel aficionado. We covered many topics including my unique approach to life, challenging societal norms, psychedelics, AI, being your authentic self, and much more.
In this episode, I welcome back Fabrice Grinda, a seasoned tech entrepreneur and investor. Fabrice shares his journey from his early days in France to building tech companies and investing in over 1100 startups through FJ Labs. We delve into his unique approach to life, challenging societal norms and embracing authenticity. Fabrice discusses his transformative experiences with psychedelics and how they influenced his personal and professional life. We also explore the role of AI in modern business, with Fabrice explaining how every company he invests in utilises AI in some capacity. He introduces Fabrice AI, a digital representation of himself, designed to answer frequently asked questions from entrepreneurs. Throughout the conversation, Fabrice offers insights into the future of AI, the importance of emotional intelligence, and the value of a broad education. Follow Fabrice on his blog, LinkedIn, and Instagram for more insights into his life and work.
Below, you’ll find the show notes and, of course, you are invited to comment. If you liked the podcast, please take a moment to rate it here.
To follow/connect with Fabrice Grinda:
- Explore Fabrice AI here
- Find/follow Fabrice Grinda on LinkedIn
- Find/follow Fabrice Grinda on X (formerly Twitter)
Other mentions/sites:
Transcription courtesy of Flowsend.ai, an AI full-service for podcasters:
Minter Dial: Hey, Fabrice cuz, great to have you back on the show. I have always enjoyed what you write about. You spark ideas, you share a lot of information, and in one of your recent posts, you talked about Fabrice AI, and boy, did that get my gander. So, let’s start with, for those who don’t know you, who the heck is Fabrice Grinda?
Fabrice Grinda: Pleasure to be on the show. Again, a little bit of background, I guess. I’m French originally, like most of the family, even though I don’t sound French anymore. From Nice, I came to the US for college, went to Princeton, top of my class, and then worked for McKinsey and company for a few years. And then at the tender age of 23, I started building tech companies. And for the last 27 years, I’ve been building and investing in tech tech startups. And actually, I kind of knew I wanted to do that from the get go. Like at age of ten, I got my first PC spilling computers, et cetera. So, I built a bunch of companies. I’ll go briefly. The last, most relevant one was a company called OLX, which is Le Bon Coin, if you want, for the rest of the world, it’s 11,000 employees in 30 countries, it’s over 300 million users a month. It’s like part of the fabric of society in most of the emerging markets, like Brazil and all of Eastern Europe and India, Pakistan, et cetera. And I guess then graduated a building venture fund called FJ Labs, where we focus on investing in mostly network affected marketplace businesses. And now we have 1100 investments in startups. We’ve had over 300 exits. And it’s super fun. And to be part of building the world of tomorrow, indeed it is.
Minter Dial: I mean, not only are you building the world of tomorrow, I feel like, Fabrice, in the amount of time that I’ve known you, you also feel like you’re developing into tomorrow the way you are.
Fabrice Grinda: Well, I think most people live lives by, like, social norms. That’s even unclear. Well, I guess if you read sapiens, who can come up with ideas of where they come from, but they’re like, oh, I need to go to high school, then I go to college, and then I get a job, and then I get married and I have two kids and a dog, and then you, your white picket fence, you want to shoot yourself. And no one actually questions. It’s like, oh, it’s societal expectations because your parents did that. And so, you tell yourself that you need to do that versus actually going from first principles. What is it? Who is it that you are, what is it that you want to be doing? Where is it you want to be living, and how is it you want to be living? And you may not know the answer to these things, but the same way that entrepreneurs basically throw spaghetti on the wall to see what sucks until they find product market fit, you can do the same thing in your personal lives, your personal life, and you can try many things and approaches in terms of what works for you. And I’m not saying that the answers I found for myself are universal, that the approach I took, I think, is universal. It’s just people are too kind of conservative is the right word, but set in the ways and not willing to try different approaches and ways of living. And I think I’ve been very good at that, living the life I am meant to be living and just be living my best life through being my true, authentic self, which I think most people find it hard to be themselves as well. For some reason, they, like, feel they need to hide and, like, especially in the, you know, this woke world where people are afraid of being canceled by for no reason, often.
Minter Dial: Well, lots of words that are off territory. But I mean, the funny thing is families, of course, you now have a dog and two kids.
Fabrice Grinda: I do. But that is by choice. And through iteration. I was actually for the longest time against the idea of having kids. It was like all my friends with kids, they disappear as the individual or even as a couple. They become the parents, and their life seems to have ended. And even though they claim that sometimes they’re happy, for the most part, when I meet them, and it’s extremely rare, it’s like every six weeks, they’re always complaining about the lack of time they have and how their kids have ended their life. But what changed my mind, actually, is I did one of these hardly non-traditional journeys or path. I did Ayahuasca ceremony in 2018. And in said journey, my grandmother, who had passed at that point for almost 20 years, Mamie Francoise, who was the matriarch of the family and the one who’s the gathering point, putting, getting together. We’d all meet around her, typically for both the summer vacations and Christmas Eve candy Seabian. She said, you know, you are living your best life. You’re living your life’s purpose. Everything’s amazing in your life. And I understand why you wouldn’t want to change anything because everything’s perfect. And look at all the people around you in the ceremony, and they’re all, like, purging and having a horrible time because I think the messages that are being given probably not as delightful. That said, there are a few things on the margin that I think you could do better than you would be a net benefit of your life. Now, the reason you’ve been resistant is, a, you don’t see the benefits of having kids, and b, you understand the costs. Well, let me. I am here to tell you that the costs are lower than you expect them to be, because instead of, you lead a non-traditional life, non-traditional relationship, you don’t need to have a traditional parenthood. Instead of living for your kids, which has become the helicopter parent model of, like, these hyperactive tiger moms in New York. Performative parents, often performative. Yeah. You can live with your kids instead of them being a substitute for your life. They can be a compliment to your life, and you can take them hell, skiing, and you can do all the fun adventures, so you can do all the things you have right now and have kids. And by the way, no one’s articulating necessarily effectively why having kids will be amazing for you. But you like to teach, you like to speak, you like to teach classes at Harvard, at Stanford, et cetera. You’re going to actually teaching someone that you recognize yourself in is going to be even more valuable, and it’s going to be a fun adventure. By the way, you’re a big kid, and so it’ll give you all the excuses you need to be even more of a kid. So, you should have a boy and a girl, because the relationship between a father and a son and a father and a daughter is not the same, and both are enjoyable. And also, having a sister will make your son a better man, and having a brother will, like, toughen it up and make your girl into a tomboy, and she’ll be super fun, and you’ll love both. And she said, have the boy first, have the daughter later, have a two-and-a-half-year age gap. And so, also in that same ceremony, I got the message of, if you try something really hard and it doesn’t work, it’s probably not meant for you. Which led me to leave the Dominican Republic, where I’d been for seven years, and moved to Turks and Caicos after a bunch of island shopping. And I also got visited by a white german shepherd, which I didn’t know existed as a dog. And the message I got there was like, look, you’re leading a. You’re. You’re a shining beacon of light in a universe of darkness, and you need an epic white dog to go along with this beautiful vision of light and you thought I’m, you know, through Game of Thrones. Dire Wolf. Ghost was only CGI, but no, it’s based on actual dog, and I exist. You need to find me. And now we have her pharma so white, she blends into the bed sheets in the back. Angel. Now, it took years to put all that into place, so after that, I had to find try to have kids with my partner. It didn’t work. Then I had to find an egg donor that looked like her meta or IQ requirements, and then I’d find the right dog breeder, et cetera. Here we are, I guess, now, six years later, with a three-year-old, a six-month-old, and a one year old puppy. And life is actually amazing. And my grandmother was right. The two kids and the dog were amazing. Don Wright. As a beautiful compliment to an otherwise joyful life where we have a blast, and I also won the baby lottery, they’re always happy. They never cry. They sleep through the night. They seem to be precocious, smart, and fun, and we have a blast. So, yeah, it’s been amazing.
Minter Dial: I love it. In the funny realm of anecdotes, in my family, I’m the older brother, younger sister, two and a half years younger than me. I have a son and then a daughter who is two and a half years younger than her son, her brother. So, somehow it feels like a natural instance. You mentioned ayahuasca, and this process of getting to know yourself, it’s something that intrigues me tremendously, and I feel is one of the ills of society is how people don’t know themselves. What was your process, and if, to what extent psychedelics participated in helping you to get to know who you are?
Fabrice Grinda: I kind of felt I always knew who I was, and I was always high iq and high energy and entrepreneurial, tech savvy and good in school. And that was like, kind of my identity growing up. The parts of my identity which I thought about that I was wrong about was, oh, I also thought I was shy and introverted, and I ultimately realized, no, you think you’re Sheldon Cooper because you’re in an environment where you’re not surrounded by peers and you have no one to interact with and no one you want to be interacting with. And so, you think you’re shy and introverted, and also you’re younger than all your peers in school, and that took longer. So, the transition to becoming the person I make is actually through observation of life. And psychedelics didn’t play a huge role in that. They played a role in other things, and I’ll get to that in a second. When I graduated college, so, top of my class, Suma cum laude, et cetera, I built a tech company then, but it didn’t have employees. It was a sole proprietorship. It helped pay for college. And then all of a sudden, I go to McKinsey. And despite often, McKinsey specializes in hiring really smart, socially awkward people. So, kind of my people. But despite often being the smartest guy in the room, I was the least effective, because, lo and behold, to succeed in life, you need emotional intelligence, oral written communication skills, the ability to empathize with others and put yourself in their shoes, and the ability to work in teams of public speaking skills, none of which I had. And so, all of a sudden, I realized, okay, I need to bring these skill sets to me and see if they come. And the more I worked on them, the more I realized it came naturally to me. And then the final, well, the next phase of the transformation was when I started at 23 in 1998 to build my first startup. Whether you want it or not, if you’re a tech CEO, you have to be a salesperson, you have to be selling the press, you have to be selling employees, you have to be selling investors, you have to be selling business partners, and there is no room for being shy, and you’re also going to be rejected most of the time. Most of the things you’re going to try are going to fail. Most of the times you try to raise money, people say no to you. You get over fear rejection rather quickly, and you become rather good at repeating stories, selling yourself, selling the company, selling the fishing, to the point that actually, I realized I actually kind of liked it. I was really good at being, talking to investors, talking to the press, talking to employees, talking to business partners. And it came naturally to me. And so, all of a sudden, even though that adventure failed my first company, I went from zero to hero, back to zero again after the bubble bursts and lost everything. And I thought, okay, maybe tech. Even though I want to be a tech founder, it’s probably not where I’m going to make money. But it’s okay. I didn’t do it for the money. Build something out of nothing. So, let’s go build the next company. It’s going to be this niche little thing, but it’s okay. It’ll be fun. But then I realized, you know what? If I’m this passionate, confident extrovert in my business life, I probably am that, too. In my personal life. It just so happens it’s never expressed itself because I assumed I was an introvert and I was shy, et cetera. But, you know, I’m 27, and the rest of the world seems to value these mystical, beautiful creatures that are women and also friendships and even family relationships, none of which I’ve invested in. Perhaps the time has come to actually see if that personality trait that has come so naturally to me in my private, in my business life actually can express itself in my personal life. And the answer is, of course it did. And all these things ultimately came very naturally to me. And I realized how much I valued, actually, interversal relationships and friendships and relationships. And so, in investing in family, the same way that I think I was very judgmental as a kid because you judge people based on the metrics by which you’re good at because it gives you value. So, as a kid, if you’re not high iq, you were deemed by me worthless. And so, I was very judgmental with my parents. Eventually you realized that’s a value judgment. People were built the way they are, and they have their beautiful, wonderful qualities and things to bring to the table. And, in fact, you want them to be different because it’s that difference that allows us to have the quality of life and the diversity that we have today. And so, once I started to stop judging people, and it took a long time to get there, but let’s say my late twenties and accepting them the way they are and loving them the way they are, and they’re saying that really the fabric the universe says love and just appreciate everyone for who they are and what they do and what they bring to the table and just be kind. Yeah. Change our relationships with everyone for the better. And then I became person I was. And psychedelics didn’t play any role in any of that. It was more me wanting to be the best version of myself, the most successful, perhaps, version of myself, which required evolution from being a Sheldon Cooper, from the Big Bang theory to a much more probably kind version of Tony Stark. And psychedelics came later in what I would call probably more of a spiritual revolution in terms of, like, I would say as an engineer, mathematician, scientist, very definitely anti religion, definitely atheistic, but then accidentally kind of had my first psychedelic experiences where it’s like. And it led to the relationship I have today, which probably led me down the path of having kids and also led me to really having a full-on experience where I felt like I communed with the divine. And so, it actually increased my open mindedness about the nature of reality and understanding that perhaps or most likely actually, you can. This feels like it is a matrix or a simulation, and you, you can manifest, some rules can be bent and others can be broken, as Neo in the Matrix. And so, it’s led to a further reinforcement of the unity and the fact that we’re all connected and that there’s love and joy, et cetera. Now, I’m not convinced that that message is universal. Meaning I clearly get the vision in some of these psychic trips that there is yin and yang, there is black and white. And so, perhaps my perspective, because I’m an element or force of light, I see everything as love. But I’m not sure that’s the message everyone is getting, though I do think we are all coming from the same universal source, and I feel the unity of energy. I do think we are built different by design in order to create actually different experiences for each of us. So, we’re kind of all here to entertain each other. Um, is the perspective I have. I have a more thoughtful, analytical perspective on that, but we can delve into it at another time. So, you know, psychedelics didn’t leave me to be who I am, but they’ve been interesting. I got into them, and it’s really like intellectual curiosity, though. I think for many people, they can be a tool of self-discovery for healing trauma. Many people describe ayahuasca, or maybe a hero’s journey of acid or mushrooms as ten years of therapy in one night. And by the way, it is that I think it is work. You’re working on yourself. Didn’t feel like that to me, because the core message I got is like, you’re living your best life. You’re living your life’s purpose. Everything’s amazing, and yet you could do these things at the margin. And even though they were, quote unquote, at the margin, in a way, they were also fundamental. I have kids, I have a dog, I moved country. But the core essence of who I am and what I do hasn’t changed.
Minter Dial: Well, somehow, nonetheless, you had that spiritual element and that connection with the universe and that universality, which I’m glad to say doesn’t sound like a woke statement of, we all are one, we love everybody. Because that’s nonsense. But, I mean, I’m curious in terms of what you read, because obviously you read a lot of science fiction. I know that. And a lot. You read a lot voraciously. I’m wondering, in the realm of nonfiction, do you read people like Jonathan Haidt or other people, maybe Sam Harris? Do you listen to his. What stimulates you in terms of exploring the outer bounds of your intellect?
Fabrice Grinda: On the nonfiction slide, I avoid what I would consider to be business books like the plague. I find that they have one idea just repeated ad nauseam throughout the course of the book, and they’re not. I mean, if you do. And can they be useful? In some circumstances, yes. But do you actually need a book over to reduce them? I’m not so sure. You can probably summarize the four-hour workweek or nudge or any of these very succinctly in terms of what are the best practices. But I do read a lot, kind of everything, things that fascinating me or interest me. So, history of humanity, kind of like sapiens type books. I love really well written books. So, Bill Bryson, which kind of also falls, and it can be history of science, like a short story of nearly everything, was definitely not short. And it’s really only the history of science and the men and women behind the science. But Bill Bryson writ large, but yeah, love Alan Watts, love Sam Harris, love Aldous Huxley. Right? The doors of perception. We go down that path. The love biographies of the people that I find relevant to me. So, Augustus or Octavian, if you want, Alexander Hamilton. So, Ron Chernow, Walter Isaacson. But overall, I’d say nonfiction is probably. Look, I read probably 50 to 100 books a year. Nonfiction is probably a third of that. But I read fiction and nonfiction for the same objective, like curiosity and entertainment. I’m not trying to get anything out of it. I read it for the pleasure of reading, you know, like, one of the most thoughtful, philosophical books I read or actually occurred. I listened to an oddball usually read. I read faster than I listen to, and I hate listening and accelerated. It was actually Green Lights by Matthew McConaughey. And Green Light, you would think, you know, he’s an actor. What level of insight could he have? But the combination of his, like, beautiful draw and actually very clairvoyant perspective on, like, what is it to lead a meaningful, beautiful life full of green lights actually made a lot of sense. So, yeah, I guess far and wide, wide in range. And speaking of the fiction is like, every type of Sci-Fi you can imagine, from, like, just entertaining to hard Sci-Fi to thrillers to fantasy, you name it. So, I read kind of everything. My only requirement is that it be good and by good, typically, I would say if it’s 4.5 or more on Goodreads and or Amazon reviews by the public, not by the critics, it is going to be good. Kind of like I don’t agree with the critics often because they will give merit to things on artistic merits or like, they’ll see a movie and it’s like, oh, the cinematography. Saying “Cinematography was groundbreaking,” but if it’s like, boring like hell, it’s not going to appeal to me. So, a surefire way to know that I’m not going to like a movie or a tv show is if the critic reviews are high and the public reviews are low. Clearly. I mean, I’m a product. I’m a man of the masses, a man of the people, because I agree with the people. And I want like 90% plus rotten tomatoes, like 8.0 or more on IMDb for me to consume tv or movie media or content, for instance.
Minter Dial: Of course, as a filmmaker myself and a book or a nonfiction writer, I’m thinking about all the freaking stars or not I have on my books. You being a guy with a high IQ, I’ve always respected your intelligence, and as such, you always bring very strong reasoning to everything. And one would imagine that you would have to believe that reason and intellect is a guiding principle. Yet a book I just read called the Righteous Mind by Jonathan Haidt, who wrote the other great book called the Coddling of the American Mind, he talks about how it’s not about reason. Reason is just a sort of an internal lawyer to justify everything we do. The big thing that drives everything about us isn’t just emotion, it’s intuition. This is sort of a very vague concept, but it seems to be much more the driving force of everything we do. And I was wondering to what extent that relates to you or how that resonates with you.
Fabrice Grinda: The idea resonates a lot because I think it’s clearly demonstrable fact. If you want to convince someone using facts and logic and reason does not work, you clearly need to appeal to their intuition, to their emotions. And thanks something Daniel Kahneman, the Nobel in economics, for what he wrote out in his book think fast, slow points out, is like you have people have immediately responses from their autonomic nervous system, which are driven by intuition, emotion, whatever you want to call it, and changing their perspective. That is hard. You need to force them to slow down and look at the data, et cetera. And for the most part, it is not compelling or convincing to people. So, absolutely the best way to engage with people, to convince them of anything is emotionally and intuitively, even though my mind I feel, um, is driven by logic and reason as an engineer, mathematician myself. And so, it actually takes or took a fair amount of effort to change the communication style and not just like bombard people with like data and statistics and charts, et cetera, in order to have engaged conversation, because I know it’s not the most effective way to get across to people.
Minter Dial: Yeah, well, as you said, facts don’t sell, and you presumably went through a lot of that in your work as you were selling yourself, your businesses, ideas. All right, so let’s talk about FJ Labs. Youve got these huge number of startups you’re investing in. You’re managing so many businesses and startups, you’re in touch with so many. So, the frontier of what’s going on, and I do want to get into the fabrics AI, which is the reason why I really picked this up. But how often is AI a part of, and has to be a part of, or should not be a part of any of the initiatives you’re investing in?
Fabrice Grinda: So, every single company we invest in uses AI in some way, shape or form. We are the early adopters. I often describe VC’s and founders as people who live in the future. We’re inventing and building and adopting the things that other people will adopt in the future as it becomes more common, mass market, easier to use and cheaper. And AI is going to transform our lives in a more meaningful way than anyone can anticipate today. But it’s also going to take longer than anyone can expect it to be. So, what happens with all these new technologies? When they become available, they become overhyped. There is a kind of a bubble of hope and excitement and things. People expect that everything will transform in the next few years. Then they disappoint inevitably and then ultimately transform our lives and societies way more than we expected. And that was true of everything from electricity to the car to planes to the radio to tv, and now to the Internet. I mean, the ideas of the late nineties, pets.com, Etoys, Webfan, were all viable. I mean, not then. The business models didn’t exist. There were not enough users. There was no GPS for doing like delivery for Cosmo or whatever. But the ideas were finally good. It’s just the infrastructure to support them was not there. And they all became viable 20 years later. And now you have Chewy inside of pets.com, which is a multi-billionaire company. You have Instacart in the grocery side, et cetera. AI is probably living at a similar moment. Venture investing peaked at around 200 billion a quarter in 4Q of 2021, and it’s now down to like 60-70 billion a quarter. So, it’s down like 66%, basically 75% peak to trough. But actually AI investing has exploded completely. And people were investing in AI companies that I find are not that compelling, like most of them were like co-pilots or non-differentiated companies. Everyone goes like stabbing, I’m building an AI company and it’s basically using a, a non-proprietary data model or LLM on non-proprietary data with no business model, and they’re raising it in same valuations and it’s going to lead, I think, to many of these companies failing to find business models, and there’s too many chasing the same ideas, and many of them are features rather than actual companies. And as a result, chat-GPT or OpenAI can just add them to what they’re doing and probably eliminate many of these companies kind of automatically. Not to say they’re not going to be verticals and winners, etcetera. So, specific AI companies that we invest in have been far and few between. We only invest in vertical AI applications, on proprietary datasets, in categories where there is a proven business model. So, we’re investors in a company called NumerAI, which is basically a stock market prediction model where people upload their models. Obviously, you need to be a kind of a mathematician to even participate. And then they all fight it out and the most successful ones were invested in, and then the part of the proceeds are returned to the people who build the models. And AI there obviously plays a huge role where investors in a company called Photo Room, which uses AI to clean the background of images to increase the sell through rate of marketplaces. Of course, something near and dear to our hearts, the company, I think is doing like $80 million in revenues and crushing it. And it’s not only remove the background, it might be put the best background and increase the sell through rate based on the category and the item you’re selling. Also, you need to realize incumbents have a pretty big advantage in AI, or should have, because they have all the data. That’s why if you look at the publicly traded companies, the Googles and Facebooks and Amazons, the combination of their data centers and the data they have, have increased their market capitalization dramatically. But it’s also true in verticals. So, for instance, we’re investors in Rebag, which is a handbag marketplace. They have all the data, handbag transactions. They’ve created this AI called Clair. Take a few photos of your handbag it’ll tell you the model, the year, the condition, whether its rake or not. It will write up the title, the description, set up the price, and it’s sold in five minutes. Much better experience than you can imagine having on a Le Bon Coin, Craigslist or eBay. Specific AI companies we haven’t invested in money because we felt that valuations were too high. The approaches were not differentiated enough. We’ve done a few verticals, giving you a few, but we’ve done many more. We’ve done some in defense, et cetera. But every single company we invest in uses AI. Everyone is using AI to improve its customer service responses. Everyone’s using AI to improve your sales team. And in fact, there’s a company called People AI. When you implement it, you turn your mediocre average salespeople to be almost as effective as the best salespeople. Everyone’s using AI to code more effectively, and it’s the same thing. All your best developers become way more productive, and even your average developers become better. It’s lowering costs, it’s increasing speed at which you can deploy products. And so, every single company we invest in, I would describe as using AI, but they would not necessarily describe themselves as AI companies. If they’re a marketplace for petrochemicals, they use AI, but they’re not an AI company. They’re really a marketplace for petrochemicals. And so, probably the asset is actually now it will transform our lives in ways that we can begin to fathom once it starts seeping into the largest components of GDP. Now, if you look at the economy today, most of GDP is the government, 30% to 45% of GDP, or 57% in France, if you want, depending on where you are. So, before government starts implementing AI effectively to lower cost and increase efficiency, I think it’ll be a long time, if only because of backlash from public sector unions whose jobs would be threatened, and large enterprise. But again today, AI has issues. You have hallucinations where it literally makes shit up. And so, if I’m a healthcare processor, am I getting a mercer? Are they going to be using AI to be doing claims processing on the medical side? Probably not anytime soon, because they don’t want to get sued for getting it wrong. Now, will it happen in 10, 15, 20 years? And when it does happen, will it lead to an extraordinary productivity revolution? Absolutely. So, I do think it’ll be more transformational than people expect, but it’ll also take a lot longer than people expect, which is kind of has been true for most technologies. But AI is here to say, and everything we do is AI. Now, as I said, all of our startups are early adopters, because if. If we screw up, it’s not a big deal. If you’re a little. If instead of selling you the very best whatever widget I sold you, a slightly different one. It was wrong. Eh, it’s okay. It’s not the end of the world. We’re not, like, mission critical.
Minter Dial: One of the things that’s funny about this conversation is you mentioned hallucinations. That’s the second time we’ve gone into hallucinations. I always liked the idea, and in my mind, I tend to believe that whether it’s psychedelics or AI, we tend to hold it to a higher standard than we hold ourselves. And we like to quote the time, the guy who took LSD and jumped off a building 15 years ago. Oh, well, look at that. We shouldn’t do LSD. Oh, look, there’s an LLM that hallucinated. Well, we shouldn’t use it because it’s not perfect. And yet, I mean, in both cases, psychedelics and AI, we’ve got amazing opportunities.
Fabrice Grinda: Oh, for sure. Look, the thing is self-driving. People are afraid of self-driving. Self-driving cars already work better than human, drive better than humans, and yet we won 99.999% efficacy from self-driving cars, even though humans are imperfect.
Minter Dial: And I think 16 million deaths a year on the road because of human error.
Fabrice Grinda: Exactly. And, like, 500 million car accidents, something ridiculous every year. And it would be a fraction of that with the level of technology we have in self-driving today. So, it takes a long time for culture to adopt so these things to become acceptable, but it will happen eventually. It keeps demonstrating that it’s better. I’m so optimistic about the potential for AI for, and I see it improving or changing their lives in ways people don’t necessarily anticipate. We haven’t had a big humanoid robotics revolution, and I think we’re on the verge of having one. So, we invested in an extraordinary company called figure AI figure. And they create humanoid robots with, like, full dexterity, manual dexterity with their hands, and they can walk around. And they’re currently active in, like, a production line in the BMW plant in Germany. And again, they’re doing repetitive tasks of, like, moving it, something there from there and putting it, which is not a job a human should be doing, honestly. And the ambition is to replace humans in, like, last mile picking and packing warehouses for, like, the likes of Amazon. Again, like, putting items in boxes, carrying the box to a Fedex or Amazon delivery truck, not jobs that are particularly well suited for humans. And the progress we’re seeing there, in terms of, like, each evolution of the robot, in terms of efficacy, ability to learn, improve, et cetera, is such that I can see it really becoming, getting a point where a decade from now, from nothing, today, we essentially will have billions of humanoid robots running around. And it’s enabled by AI. If AI wasn’t as good as it was in terms of speech, uh, recognition, response, understanding of the world we’re in, it would actually. That wouldn’t work. So, it’s both a software and a hardware problem. The hardware problem is not to be scoffed at, but it is only enabled because AI has gotten so good.
Minter Dial: You mentioned at the beginning you’ve invested in, I think you said, 1100 startups, and I would imagine that most of them are us based or North American based. We talked about robotics. You just mentioned BMW in Germany. Certainly, if I were thinking about robotics, I would think that Japan is at the forefront, cutting edge of that. I was wondering if you could react on that and to what extent or how many of your investments are actually more extra-US, or at least more global?
Fabrice Grinda: So 50% of our investments are in the US, 50% of the rest of the world. Of the rest of the world, about 25% western Europe and the Nordics, 10% Brazil and India, and 15% of the rest of the world.
Minter Dial: Is that by design, by the way?
Fabrice Grinda: No, it’s completely bottoms up. We see deals, we have deal flow, it’s coming in globally, and we invest in the ones that we like. Now, the only things that are by design or intentionally avoiding Russia, China, and to a lesser extent, Turkey, because the political decisions that they’ve made of is leading to macroeconomic consequences, and microeconomic consequences at startup level, that make it way harder to see whether or not it started, or a company that you can invest in that could be, would otherwise be extraordinarily successful, may fail for reasons outside of its own fault. So, I was obviously an early investor in Alibaba. Did extremely well there. I stopped investing in China after Jack Ma was disappeared. And I’m a big investor in ant financial, the payments company. But they were supposed to go in a $250 or $300 billion IPO, and that never happened. And who knows when, if ever, that will go public, and how Xi Jinping feels about it on any given day? Same thing. We’re big investors in Russia until 2014. And so, when Russia invaded Crimea, all the US VC’s that were funding the Russian companies basically pulled out. And so, all of our unicorn startups in the country basically were taken over for pennies in the dollar by oligarchs and the entire category evaporated. And same thing in Turkey. After Erdogan, the western investors that are VC’s are mostly in the west that were scaling the companies, took flight and fright, and that destroyed many of those companies. So, we’ve been way more careful. But other than that, no, it’s totally bottoms up. And here’s what’s interesting, there’s been a total democratization of startup creation. In 1998, you needed to be in Silicon Valley because you needed computer scientists from Stanford. That was the only place where you had the skill set, you needed the VC’s from the valley. That’s the only place where there were VC’s. And when you were building a startup, you were building your own data centers and computers and everything. Then came the open-source revolution, so MySQL and PHP, which made things cheaper. Then came the AWS revolution, where you put everything in the cloud, so making things even cheaper. Then came the low code, no code revolution. Now with the AI revolution, you no longer need even to be a computer scientist, your ability to build something, so it’s cheaper, easier to build something than it’s ever been. And so, all of a sudden we’re seeing non-traditional. So, first it led to the explosion of secondary ecosystem. So, you started seeing Paris and London and Berlin and New York and La, et cetera, not just San Francisco. And then you’re starting to see now an explosion, not only in other cities or countries like Indonesia and Vietnam and India, et cetera, but you’re also seeing it in the secondary and tertiary cities, both in the core ecosystems and elsewhere, because you no longer need to be a computer scientist from Stanford, you could be a art history major, and you have a vision for something, and you no longer need to find, like a nerdy friend who coded for you, you might be able to actually get it coded reasonably easily.
Minter Dial: Now, you wrote in one of your articles, timing is everything, about how AI is helping to democratize startups. That was something I was going to talk about, but I’m wondering, you just mentioned art history or something like that. To what extent do you think liberal arts is a viable area of study? Is that something you would sway your two kids to do or against?
Fabrice Grinda: So I always thought the point of a college education in the US, liberal arts or not, is actually intellectual curiosities. Pursue your passions and interests, but I wouldn’t specialize. Right? Like when I went to college, I studied, you name it. I studied like Peloponnesian war and roman empire and multivariable calculus and electrical engineering and molecular biology. And I majored in economics and economics to be explained the way the world worked. Now, none of that I effectively use today the level of math I use rather the level of math I achieved. I haven’t run a regression, I think, in 20 years.
Minter Dial: Where’s your HP calculator?
Fabrice Grinda: So, I’m not so sure. That said, would I encourage everyone to learn a program? Absolutely. Would I encourage everyone to understand basic accounting and finance and economics, to understand how the world works? Absolutely. But would I specialize in whatever, art history? No, but is in knowing and understanding history, I think. Interesting. Yeah. Some of the most interesting people I know, and the most successful actually were philosophy majors and Reid Hoffman at LinkedIn or Peter Thiel are both philosophy majors. And so, I pursue my curiosity and I would sprinkle in though things that are practical. So, I would definitely not major in art history, I would definitely not major in diversity studies or whatever. So, yeah, computer science, economics probably would be the two categories I’d be leaning towards. But you know, the beauty of a major in the US is you need to take four courses a semester and you have four years and two semesters per year, so that’s eight per year. So, we’re talking 32 classes. And your core major I think is like eight or twelve advanced. So, you have like 20 classes. And by the way, you don’t need to limit yourself to four courses semester. It’s the same price whether you take four or six or eight now. Probably need to drink a little less, probably a little less if you want to take a to semester. But it is within your reach and your ability to study everything and anything. So, I would know. I would definitely study programming. I would definitely study economics and history, philosophy. All these things I think are fun and value add engineering as well.
Minter Dial: So you basically subscribe to the American education at the university level as I understand it.
Fabrice Grinda: Yes. But there are many majors that I do think lead down a wrong path. Right? Like. So, I would definitely not be studying art history because there is. I don’t know how many art curators of the Met positions there are per year, but not very many. Right? Like, so I would definitely not be studying music. I would. I mean, the same way I wouldn’t want to push someone to become a professional athlete. I wouldn’t. Even though we’re a family of racket enthusiasts, I actually would not want my son to try to be a professional tennis or paddle player because it leads to a monotonous life where your entire life, from age five to whatever 35, is dictated by one thing. And so, you’re sacrificing everything on an altar of something that is okay, I think. I don’t know. I just find it intellectually interesting. Is it fun, is it physically challenging? And can you be extremely successful? Many. Look, how many successful. How many people make living out of tennis? Top 50, maybe. But how many people make a living out of being in business? Billions or millions or hundreds of millions. But more importantly, I think the life is just uninteresting. You’re doing the same thing day in and day out. I value curiosity, but depends on your interests.
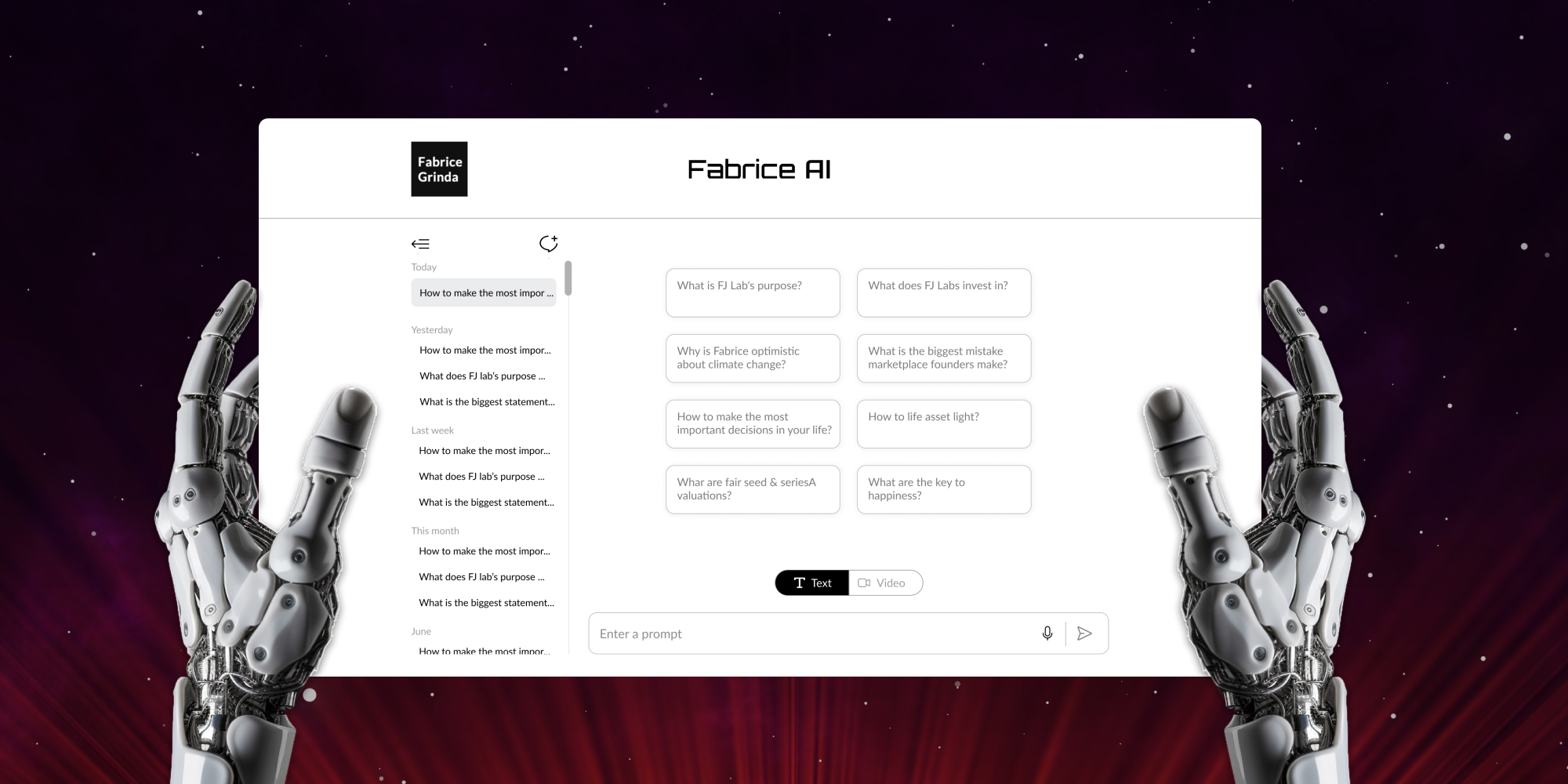
Minter Dial: I get that. All right, let’s finish Fabrice. Talking about Fabrice AI, let me put the context, which really struck me, which is that I believe that the future of AI in business will be about creating proprietary AI, proprietary data sets, proprietary learning algorithms, maybe on top of existing LLMs, at least at the beginning, but that’s what I feel, and I feel most companies aren’t there. Fabrice AI seems to me exactly in that vein for Fabrice Grinda Institute or Fabrice Inc. So, tell us about the idea and what you’ve learned in trying to create Fabrice AI.
Fabrice Grinda: So the reason I decided to build fabrics, AI, understanding that the use cases are extremely limited, it’s really intellectual curiosity. It’s like when these companies were pitching me and they’re telling me that they’re building this extraordinary AI on prime data models. How hard is that? How hard is it to build? How replicable is it? How much magic is there in the implementation of AI? All these people that are building these copilots, is it just, I bring up the data, I pump it in the OpenAI API, and then we’re done. It’s a couple of hours of work. Where is the nuance of it came out of intellectual curiosity, assuming that very few people would use it, because at the end of the day, I’m intentionally limiting the data. To your point, I do think the future of AI in most enterprise is limiting it, or at least focusing it on your own proprietary data to create differentiated responses. Fabrice AI is a digital representation of me, based on the content I’ve uploaded. And I’ll talk, and only that. So, it’s not open to the Internet. So, if I did not answer the question, it will just say it doesn’t know. It’s not open to Google and Wikipedia or chat GPT writ large, because that was not the objective. The objective is replicate me. Now, the reason it’s so interesting for me is I get a lot of inbound questions daily that are repetitive. Founders are always asking me the same thing. How do I come up with an idea? How do I validate my business idea? How do I write a deck? How do I pitch VC’s? How do I approach VC’s? When do I pitch VC’s?
Minter Dial: What are the biggest mistakes they make?
Fabrice Grinda: What are the biggest mistakes founders make? How do you find product market fit if you’re in a marketplace? How do you build liquidity in a marketplace? Or what are the biggest mistake marketplace founders make? What are the current seed and series a valuation and traction metric? I mean, I get the same questions over and over and over and over again and I have written to some extent answers to most of these and I’ve addressed them by voice. So, I’m like, okay, it’ll be somewhat helpful for founders. And my blog really is a combination of writing about things that interest me and also answering what are all the things I wish I knew. When I was starting out, I was 23 that I now know. So, it’s kind of like sharing my knowledge and sending people to a repository of data so I don’t need to repeat myself on a day in day basis. Very fair. That was really the basis of this. So, it started about a year ago and all I did at that time was basically upload all my, I have about 1000 blog posts on the blog and upload that content into the API for OpenAI. The thing is, the pricing of GPT 3.5 was like a dollar a query and GPT-3 was like one penny. So, I put it in GPT-3 and the results were awful. Now all I did and at first, and that was just piping the data in not even building an interface by which people can ask questions because that actually requires creating a search or using a search engine on my end and extracting the data and then piping it in real time. And the results were awful. And no matter what I did, nothing worked. And the responses were now I realized there were two problems. First problem was a data input problem, which is a lot of the knowledge that I share in my blog is actually not in text form, but actually is in the PowerPoints, video interviews, podcasts, just audio interviews and all those that’ll be transcribed. So, massive exercise in transcription first to transcribe all the video, audio and PowerPoints. So, I use like the Azure OCR to grab the text from the PDF’s to convert it in text to upload it. Then I had to take. But it did actually really good. It took a long time. It took a really good job. Like, it uploaded the family tree to the point that I posted in one of the PDF’s about the family in French. And so, you can ask in Chinese a question of like, who is this person relative to this in our family history? And it answers so just from reading the family tree, it’s not written anywhere in the text, so it’s actually gotten really good. But that’s iteration 500 converted all the videos and audio, but then it was not obvious to it who is the speaker? And so, it would attribute. So, if I’m interviewing someone, it would often attribute the answer of the other speaker to me, which is obviously completely wrong. And so, I then had to delineate who is the speaker. And I use GPT to actually do all that.
Minter Dial: But there’s a lot of manual interference.
Fabrice Grinda: Oh my God. The amount of like. So, I will split the job into two buckets. One is data cleaning and input, even though I’m using a lot of AI. So, I would take the, I would take a YouTube video or mp3 file, I’d upload it in one of the many programs. There’s otter AI, there’s GPD itself, et cetera. And I compared all of them to see the one that I like best. And that answer changed over time. So, which one I like best as well. Then I realized that the transcriptions were terrible, meaning Fabrice, my name would sometimes be Febreze, and it would be like CAC, it would not understand what it was. But I didn’t want to go. I mean, a one- or two-hour podcast is like, I don’t know, 20, 30, 40, 50,000 words. It was like editing books. So, I decided, you know what? I’m not editing it. The only thing I’m doing is I’m writing a script where I’m making sure that it knows that speaker one is x person and speaker two is the y person, and there’s more than that. And then it’s tagged properly. Okay. So, then I had all the audio, PowerPoint, PDF and video content separated, and I uploaded. But then obviously everything was uploaded at the date of the upload, as opposed to the date it was originally recorded. So, then I had to re upload it, pointing at what are the dates. So, I understand context throughout time, such that putting a higher weight on more recent content than older content.
Minter Dial: So, you’re giving a weighting to all the content somehow?
Fabrice Grinda: Yes. With more recent content more highly weighted than older content and certain content more weighted than others. And they’re still getting most of the replies wrong even when I was using GPT 3.5. So, then I’m like okay maybe I can use so Chat GPT as a app store where for free by the way you can actually just build an app and paid subscribers of OpenAI Chat-GPT can have access to the app store, redid the same thing, uploaded all the content there. This way I didn’t need to deal with everything else and I’ll talk about what the everything else is because everything else is actually rather complex and the results were better but still not very good. And the limitations of that were that I could not embed it in my blog and you need to be a page writer of Chat GPT because it lives in the GPT store and the results were while better, were still kind of crappy. So, then I’m like okay maybe as I’m piping the data. So, I’ve created this database, so I’ve created this index of all of the content that is now nicely formatted, now nicely dated and there’s the OCR, everything’s in text, everything’s great. Maybe it’s when I’m typing in the query and I’m sending the data to maybe it’s the problems on my side. It turns out that that was true. First I did ok what type of search? When I’m typing something in because the database is actually held on our database. You’re sending the data to OpenAI to give an answer but the queries are coming from you. I first did a vector search on a line index and that didn’t work. Then I used Mongo DB which worked better. Minter Dial: Kevin Ryan!
Fabrice Grinda: Yes Kevin Ryan startup then we did a summary tree index, I mean like just kept. Then I created knowledge graph index, then I tried different LLMs and I tried Gemini, then I did line chain documents on Pinecone. I mean you name it I probably tried it. And what ultimately worked was frankly when they finally released GPT 40 or model 4.0 and GPT and a product called GPT Assistance which allows you to connect through the API more effectively using a vector database to refine the prompts, I finally got the results but that’s like 500 hours of work later and this is something I do at night for fun by the way this is not my day job, this is like oh I’m a weekend or 3 hours to spare. Let’s keep iterating on this where I got to the point where it’s happy which is in July of this year, I still have things to fix and incorrect answers, etcetera. I decided then, now I’m happy with the results. Let’s go build a UX UI that looks like chat GPT and that both in mobile and web. So, that took a little bit of time. And then I decided, okay, I want to have the same the ability for people to ask a question by voice and then get the text response. So, then I needed to build a voice to text transcription product. So, I tried two approaches, actually there is a voice of text API offered by OpenAI called Whisper. The thing is, I call the API, I send the text, I send it there, they transcribe it, they send back the response, I then send it to my database, which then sends the data to GP assistants to get the results. I was not happy with the latency. Ultimately I decided this part, I’m not sending a whisper, I’m doing it on server here, but with the exact same UX UI as GPT, which is why I have a start recording and stop recording. It’s not like WhatsApp where you remove the finger and it stops reporting and yeah, release and it’s working shockingly well now. Again, it actually gets more usage than I expected. It gets as much traffic as the rest of my site with really interesting questions. And people were asking even very specific questions of like what do you think of this as well? And this approach is vertical and the answers are more nuanced and interesting than I expect them to be. I think one of my upcoming blog posts I’m going to do a best like what are the top, the most interesting questions and answers I’ve seen, just because it’s been more impressive than possible now, people also asked a lot of personal questions, which the AI doesn’t have the answers to. So, what I’m currently doing, but it’s a lot of work, manual work, that I’m the only person who can do is I’m currently. So, for my 50th birthday, people made a beautiful video tribute. So, I’m actually transcribing the video tribute into text and uploading it. And it’s both in French and English, but it doesn’t matter, you can upload it and it’ll translate automatically and I’ll upload it so people can understand what my friends would think about me, who my friends are. Because right now if you ask who my friends are, it actually answers things that are completely wrong. Because it’s based on posts where I took photos with friends from 30 years ago or 20 years ago. And the issue of course is there for every person who talks, there’s no name in front. So, I actually have to go through all the texts and add the name, the full name and the relationship to me for each person. So, I’m in the process of doing that as we speak. It is slow. So, that’s the next thing I’m going to upload, and then the next thing I’m going to upload a Fabrice AI. I’m trying a product called the HeyGen and I’m scanning my face and voice to try to create an interactive version of me. I tried many other. Yeah, the Avatar. So, you can actually have a conversation with a digital version of me? Probably. I mean, I tried four or five of these products. They’re all very expensive, like 10,000 a month or a year, et cetera. The reason I’m choosing HeyGen is because it’s like, I don’t know, x dollar, ten for 30 for a lot. I don’t remember the price, but not a lot for a lot of minutes of interaction. I don’t suspect there will be that much usage. And so, it’s a variable cost, no setup fees, no minimums. It’s like 20 or $30 a month. And it’s viable for someone doing it for fun with no real business model in the backend. And it is going to be a lot of coding, but I think it’ll be fun. Now, again, lesson learned is I could probably wait for GPT-5 or GPT-6 and probably leave all include for free a way to digitize myself and not use Hadron. But you know what? The point is not to make it easy. It’s like to see what’s wide, who’s doing wide, what is interesting. But it’s definitely given me an appreciation for people building AI models out there that it’s a lot harder to get things right than I expected.
Minter Dial: Well, I mean, I love the fact that you’re doing this. I mean, the fact is that you are experimenting, you’re playing with it, you’re doing hard work, really going down into nuts and bolts and all this cleaning of the database, the tagging and everything. It seems like a monumental work. I’m wondering to what extent you would now say that your database is structured or would you still call it unstructured?
Fabrice Grinda: Oh, no, it’s fully structured. Well, here’s what’s interesting, is I didn’t need to tag it. So, it’s unstructured in the sense that it’s not tagged much. There’s maybe a category prioritizations. Oh, yeah, but now the conversations is, it’s way more structured than ever, and it’s also easier than ever to structure, because now, whenever I do one of these, I have it auto transcribed. I include the transcription in the blog post. So, when I upload, so every new blog post I upload is now auto translated, first of all, and uploaded all the. And I think I picked, like, I don’t remember, but like 26 languages or whatever, the top 26 for 30 languages in the world. So, it’s auto AI translated in all the languages, I upload all the translations, and I do all. If I do a video interview or whatever, or podcast, the text is, I include the transcription in all the languages and upload it. And it’s always added automatically to the Fabrice AI repository. So, it’s way easier than it’s ever been. And by the way, as I said, I don’t proof it, so even those transcriptions are not perfect. I just make sure that the answers it gives from that are good by doing two or three QA questions. And for the most part, it actually works.
Minter Dial: Well. If I could just put in front of you another friend of mine who launched a company called Flowsend.AI. F l o w s e n d, which is particularly useful for podcasters because it really helps this idea of identifying speakers. It also is available in multiple languages, and it provides a whole spew of relevant content to help propagate, socialize, all the content that comes from it. Anyway, that’s my identity.
Fabrice Grinda: That’s really cool. I’ll play with it. Look, for instance, when you post this, I’ll repost it on my blog, and we should definitely have 26 transcriptions and the features identified, etc, etcetera.
Minter Dial: So, I’m just. Just for people who are not familiar with you and your work, I went on it and I enjoyed very much playing around with it. I went and specifically went in, what is FJ Lab’s purpose? And then from there I say, what is purpose for you? Which I was just talking to the bot, right. I wasn’t really thinking Fabrice, necessarily. And then all of a sudden, the response came out, well, my purpose is to solve the world’s problems in the 21st century, focusing on equality of opportunity, climate change, and the mental and physical wellbeing crisis through technology, especially marketplace and network effect businesses. So, that is what your bot said.
Fabrice Grinda: And I assume I would say that that’s true as well. For me. Exactly. I agree with Fabrice, the individual, which is good.
Minter Dial: Hey, it was a fact check. All right, listen, Fabrice, super. Thank you so much for coming back on. Great to riff with you. I really got a big buzz listening to you. How can people follow you? Obviously see your blog. What other links would you like to send them to?
Fabrice Grinda: Blog is probably the easiest. You can also follow me on LinkedIn, @FabriceGrinda there and on Instagram if you want to see photos of my kids, basically, which is all I post or for my dog, at all times. But yeah, my blog is really the best way to follow me.
Minter Dial: Right? Hey, listen, Fabrice, thanks very much.
Fabrice Grinda: You too.